Apriori算法:从数据中挖掘频繁项集
简介
Apriori是一种流行的算法,用于在关联规则学习中提取频繁项集。Apriori算法被设计用于对包含交易的数据库进行操作,例如商店客户的购买。如果项目集满足用户指定的支持阈值,则该项目集被视为“频繁”。例如,如果支持度阈值设置为0.5(50%),则频繁项目集被定义为在数据库中所有事务的至少50%中一起发生的项目集合。
定义
支持度(support):support(A=>B) = P(A∪B),表示A和B同时出现的概率。
置信度(confidence):confidence(A=>B)=support(A∪B) / support(A),表示A和B同时出现的概率占A出现概率的比值。
频繁项集:在项集中频繁出现并满足最小支持度阈值的集合,例如{牛奶,面包}、{手机,手机壳}等。
强关联规则:满足最小支持度和最小至此年度的关联规则。
算法步骤
- 从记录中计算所有的候选1项集,并计算频繁1项集及支持度。
- 由频繁1项集生成k项候选集,并由k项候选集计算k项频繁集。
- 用k项频繁集生成所有关联规则,计算生成规则置信度,筛选符合最小置信度的关联规则。
Apriori原理
任一频繁项的所有非空子集也必须是频繁的。也就是当生成k项候选集的时候,如果候选集中的元素不在k-1项频繁集中,则该元素一定不是频繁集,这个时候不需要计算支持度,直接去除即可。
比如说我们有0,1,2,3组成的集合,下面是其所有的项集组合:
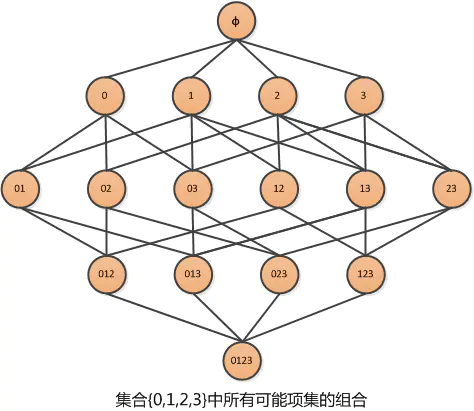
从1项集开始计算k项集的支持度,在2项集候选集中当我们计算出{0,1}集合是非频繁的,那么它的所有子集都是非频繁的,即2项集{0,1,2}和{0,1,3}也是非频繁的,它们的子集{0,1,2,3}同样是非频繁的,对于非频繁集我们就不需要去计算支持度。

当找出所有的频繁后需要从频繁集中挖掘所有的关联规则,假设频繁项集{0,1,2,3},下图表示其生成的所有关联规则,对于阴影部分的低可信度的规则,它们的子集同样也会是低可信度的。

Python实现
网上一些Python实现Apriori算法实际上代码不太符合python风格,另外一点就是有点不好理解,所以这里尽可能简洁的实现。
1. 数据集
使用列表表示多个事务记录,每个事务记录同样使用列表表示项集。
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
2. 创建初始候选集
这里使用frozenset不可变集合是为了后续计算支持度字典是将集合作为键。
def apriori(data_set):
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)3. 从候选项集中选出频繁项集
如下图所以我们需要从初始的候选项集中计算k项频繁项集,所以这里封装函数用于每次计算频繁项集及支持度,当候选项集中集合中的每个元素都存在事务记录集合中是计数并保存到字典中,计算支持度后输出频繁项集和支持度。
def generate_freq_supports(data_set, item_set, min_support):
freq_set = set() # 保存频繁项集元素
item_count = {} # 保存元素频次,用于计算支持度
supports = {} # 保存支持度
# 如果项集中元素在数据集中则计数
for record in data_set:
for item in item_set:
if item.issubset(record):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
data_len = float(len(data_set))
# 计算项集支持度
for item in item_count:
if (item_count[item] / data_len) >= min_support:
freq_set.add(item)
supports[item] = item_count[item] / data_len return freq_set, supports4.生成新组合
由初始候选集会生成{1,2,3,5}的频繁项集,后续需要生成新的候选项集Ck。
def generate_new_combinations(freq_set, k):
new_combinations = set() # 保存新组合
sets_len = len(freq_set) # 集合含有元素个数,用于遍历求得组合
freq_set_list = list(freq_set) # 集合转为列表用于索引
for i in range(sets_len):
for j in range(i + 1, sets_len):
l1 = list(freq_set_list[i])
l2 = list(freq_set_list[j])
l1.sort()
l2.sort()
# 项集若有相同的父集则合并项集
if l1[0:k-2] == l2[0:k-2]:
freq_item = freq_set_list[i] | freq_set_list[j]
new_combinations.add(freq_item)
return new_combinations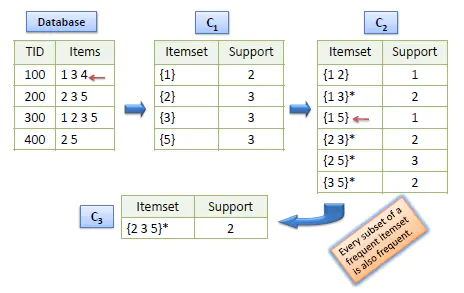
5.循环生成候选集集频繁集
def apriori(data_set, min_support, max_len=None):
max_items = 2 # 初始项集元素个数
freq_sets = [] # 保存所有频繁项集
supports = {} # 保存所有支持度
# 候选项1项集
c1 = set()
for items in data_set:
for item in items:
item_set = frozenset([item])
c1.add(item_set)
# 频繁项1项集及其支持度
l1, support1 = generate_freq_supports(data_set, c1, min_support)
freq_sets.append(l1)
supports.update(support1)
if max_len is None:
max_len = float('inf')
while max_items and max_items <= max_len:
ci = generate_new_combinations(freq_sets[-1], max_items) # 生成候选集
li, support = generate_freq_supports(data_set, ci, min_support) # 生成频繁项集和支持度
# 如果有频繁项集则进入下个循环
if li:
freq_sets.append(li)
supports.update(support)
max_items += 1
else:
max_items = 0
return freq_sets, supports6.生成关联规则
def association_rules(freq_sets, supports, min_conf):
rules = []
max_len = len(freq_sets)
# 生成关联规则,筛选符合规则的频繁集计算置信度,满足最小置信度的关联规则添加到列表
for k in range(max_len - 1):
for freq_set in freq_sets[k]:
for sub_set in freq_sets[k + 1]:
if freq_set.issubset(sub_set):
conf = supports[sub_set] / supports[freq_set]
rule = (freq_set, sub_set - freq_set, conf)
if conf >= min_conf:
rules.append(rule)
return rules7.主程序
if __name__ == '__main__':
data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
L, support_data = apriori(data, min_support=0.5)
association_rules = association_rules(L, support_data, min_conf=0.7)Mlxtend实现
Mlxtend是一个用于日常数据科学任务的Python库。
这个库是在搜索Apriori算法相关资料的时候,google给出的其中一个搜索结果,通过库的文档可以发现该库frequent_patterns模块实现Apriori算法和挖掘关联规则。感兴趣的话可以自行搜索相关文档,当然自己实现的话对整个算法的思路要更清晰一些。具体实现如下:
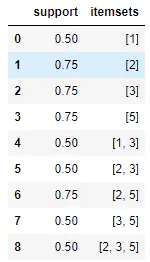
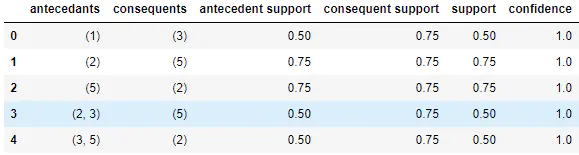
import pandas as pdfrom mlxtend.preprocessing import TransactionEncoderfrom mlxtend.frequent_patterns import apriorifrom mlxtend.frequent_patterns import association_rules data = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]te = TransactionEncoder()te_ary = te.fit(data).transform(data)df = pd.DataFrame(te_ary, columns=te.columns_)frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)rules = association_rules(frequent_itemsets, min_threshold=0.7)
通过TransactionEncoder将其转化为正确的数据格式,再使用apriori函数生成频繁项集,最后使用association_rules生成关联规则。可以看到编码后的数据实际上是特征矩阵,每个列对应的是项集元素。

作者:简杨君
链接:https://www.jianshu.com/p/fba9e41334a8
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Stable Diffusion基础:精准控制之ControlNet
Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
Stable Diffusion基础:ControlNet之图像提示(垫图)
Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程
Stable Diffusion基础:ControlNet之图片高仿
Stable Diffusion基础:ControlNet之人体姿势控制
SDXL 1.0出图效果直逼Midjourney!手把手教你快速体验!
AI抠图使用指南:Stable Diffusion WebUI Rembg实用技巧