SDXL 1.0出图效果直逼Midjourney!手把手教你快速体验!
介绍
最近,Stability AI正式推出了全新的SDXL 1.0版本。经过我的实际测试,与之前的1.5版本相比,XL的效果有了巨大的提升,可以说是全方位的超越。不仅在理解提示词方面表现出色,而且图片的构图、颜色渲染和画面细腻程度都有了很大的进步,实际出图效果堪比Midjourney。此外,该版本还继续采用开源的形式发布,对于喜欢自定义生成图片的用户来说是一个极大的福音。
在 SD WebUI上 运行时还有一个额外的惊喜,就是它直接支持绘制不同风格的图片,如下图所示:

图片来源:https://stable-diffusion-art.com/sdxl-model/#Using_SDXL_style_selector
看到这里,我想一些大模型、Lora模型确实可以进入回收站了。
那么XL现在是怎么做的呢?相比之前的出图方式,SDXL采用了两步走的方法,先使用基本模型生成有噪声的潜在图,然后再使用精修模型进行降噪优化,官方给的处理示意图如下:
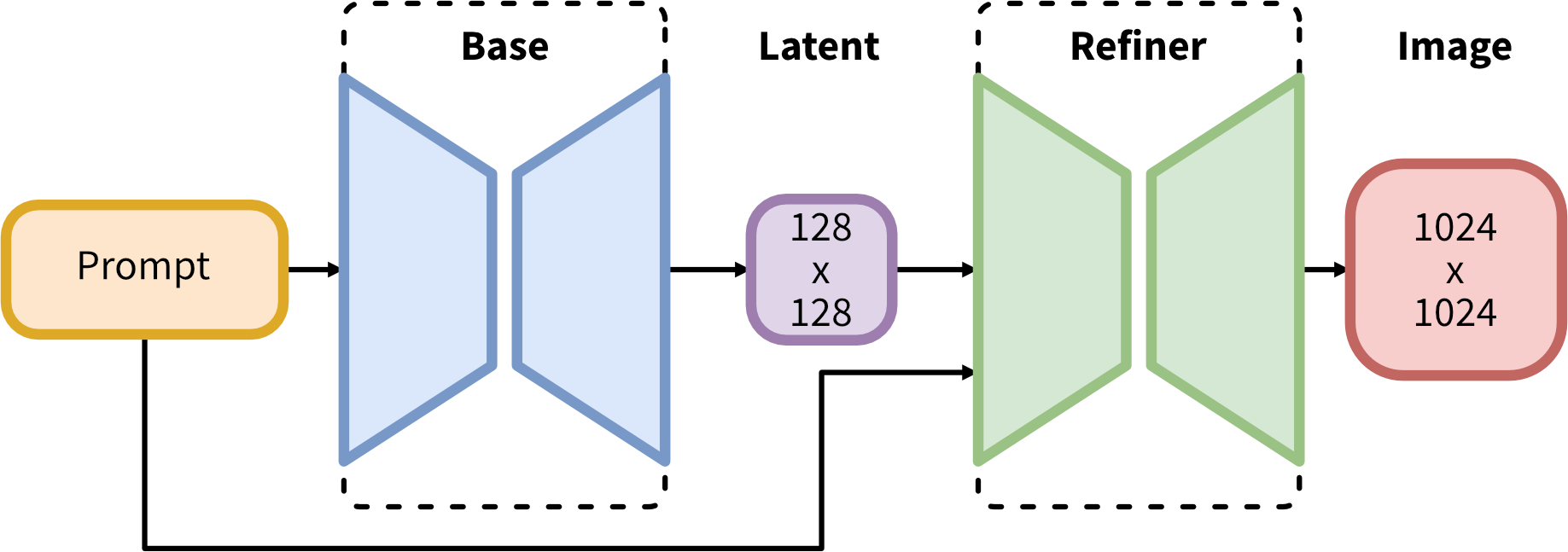
不过基本模型也是可以独立使用的。所以实际出图时也可以采用另一种方法,首先,使用基本模型生成所需输出大小的潜在图;然后通过图生图的方式,使用精修模型和相同的提示词,重绘第一步生成的潜在图,以优化出图效果。这种方法稍微慢一些,因为它要执行更多的处理。
实际使用时,需要注意以下几点:
- 负面提示:与1.5、2.0版本相比,负面提示不再像之前那么必要了。许多常见的负面词汇是无用的,比如“Extra fingers”。
- 关键词权重:对于SDXL模型来说,1.5版本的权重很高。如果你要复用1.5模型的提示,可能需要降低权重。减少权重的效果比增加权重更好。
- 安全扩散:一定要使用safetensor版本的模型,它更安全,不会在你的机器上执行代码。
- 精修强度:为了获得最佳输出效果,请使用低强度的refiner。
- Refiner:为了得到更好的效果,请使用一张有噪声的图片来使用refiner。
- 图像大小:SDXL模型的原生大小是1024×1024像素。虽然SDXL支持不同的宽高比,但图像质量对大小很敏感。以下是Stability AI官方图像生成器的尺寸,建议采用,如果需要更大尺寸的照片,可以再使用高清化放大。
- 21:9 – 1536 x 640
- 16:9 – 1344 x 768
- 3:2 – 1216 x 832
- 5:4 – 1152 x 896
- 1:1 – 1024 x 1024
- ControlNet:ControlNet现在只能在V1模型上工作,SDXL的支持还在开发中。
免安装体验
不用安装,还有N多的模型可以直接使用,不仅能使用SD XL,也可以继续使用SD 1.5;缺点是不能安装插件。
访问地址:https://www.liblibai.com/
进入后,点击页面右上角的“在线Stable Diffusion”即可进入。

按照下边的步骤操作即可。

注意第3步和第4步,这是和之前不一样的地方。
- 需要勾选XL Refiner才有精修,大家可以对比下勾和不勾的效果。
- 选择SDXL的模型后,宽度和高度默认变成 1024*1024。
分享下提示词:
提示词:street fashion photography, young female, pale skin, (look at viewer), sexy pose,(pink hair, white hair, blonde hair, long hair), ((high ponytail)),detailed skin, (detailed eyes:1.3), skin pores, (grin:1.1), skin texture, (Hunter green uniform, black skirt:1.4), long green sleeves,8k, real picture, intricate details, ultra-detailed,(photorealistic),film action shot, full body shot, in a shopping mall,realistic, extremely high quality RAW photograph, detailed background, intricate, warm lighting, high resolution,uhd, film grain, Fujifilm XT3
反向提示词:text, watermark, disfigured, kitsch, ugly, oversaturated, low-res, blurred, painting, illustration, drawing, sketch, low quality, long exposure, (cape:1.4), cartoon, 3d character
然后大家就可以愉快的生图了,每天300张。不过因为是共享的服务,高峰期可能等待的时间比较长。
云服务器体验
以 AutoDL 为例,我已经发布了一个支持 SDXL 的 Stable Diffusion WebUI 镜像,租用实例时选择“社区镜像”,输入:yinghuoai,就可以选择到这个镜像了。
没有AutoDL经验的同学,可以先看我这篇入门教程:https://mp.weixin.qq.com/s/dhklIMvkdtJygvlzUvU3xw

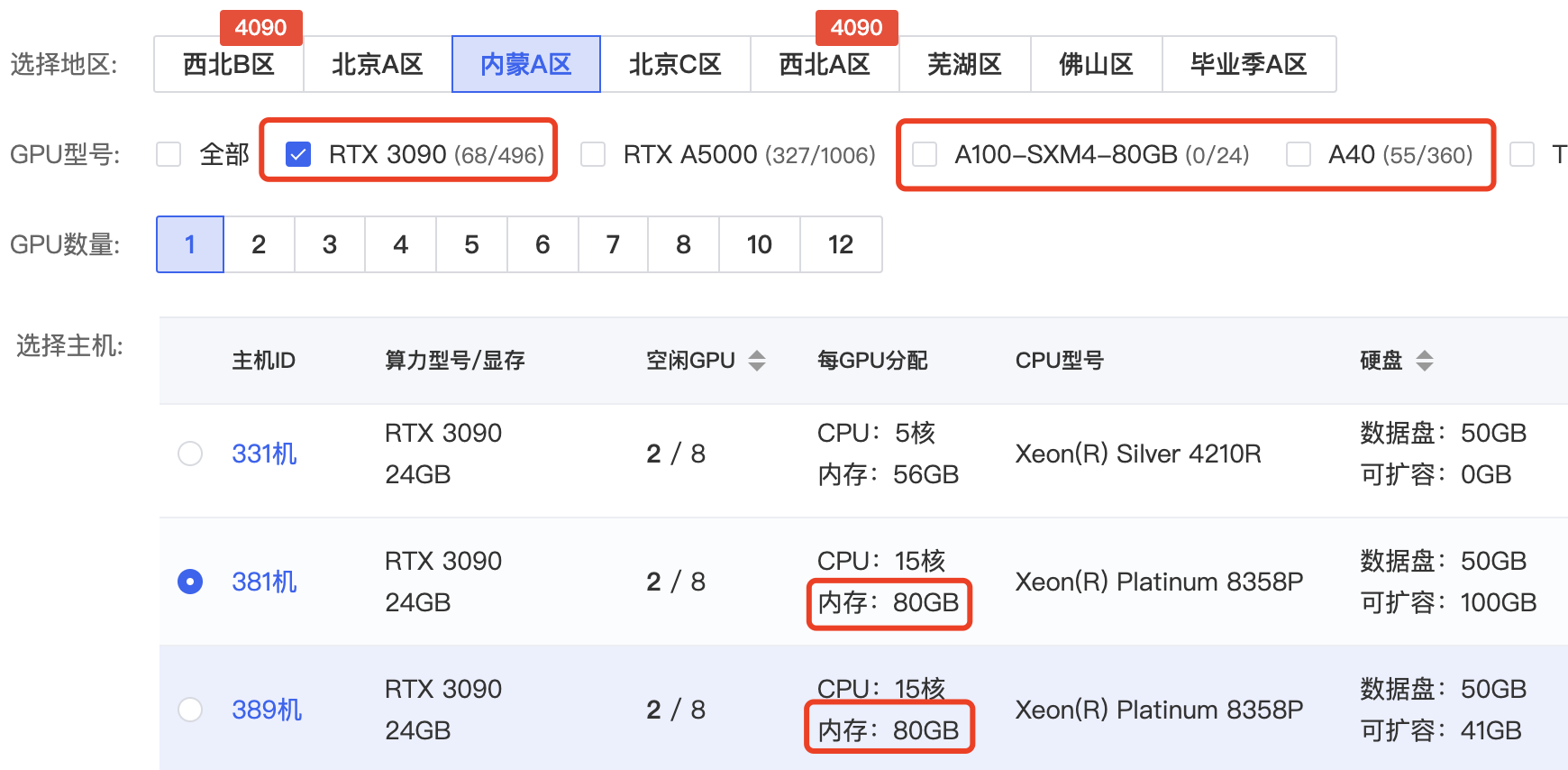
注意SDXL目前需要的内存资源比较高(可能是SD WebUI在内存缓存了很多数据的原因,单独跑SDXL Demo的时候没有消耗这么多的内存),建议选择内存在80G的主机,当然单价也会更高一些。后续我也会继续了解下如何降低它的内存和显存使用,如有兴趣请保持关注。
目前 SD WebUI 发布版本使用的是前文介绍的先“文生图”、再“图生图”的方法,虽然操作上啰嗦了一些,但测试出图比较稳定。操作方法如下图所示:
1、基础模型选择这个:sd_xl_base_1.0.safetensors
2、提示词随便写点就行。
3、宽度和高度注意手动调整到 1024*1024,实测512出图是卡通图,效果也不怎么样。

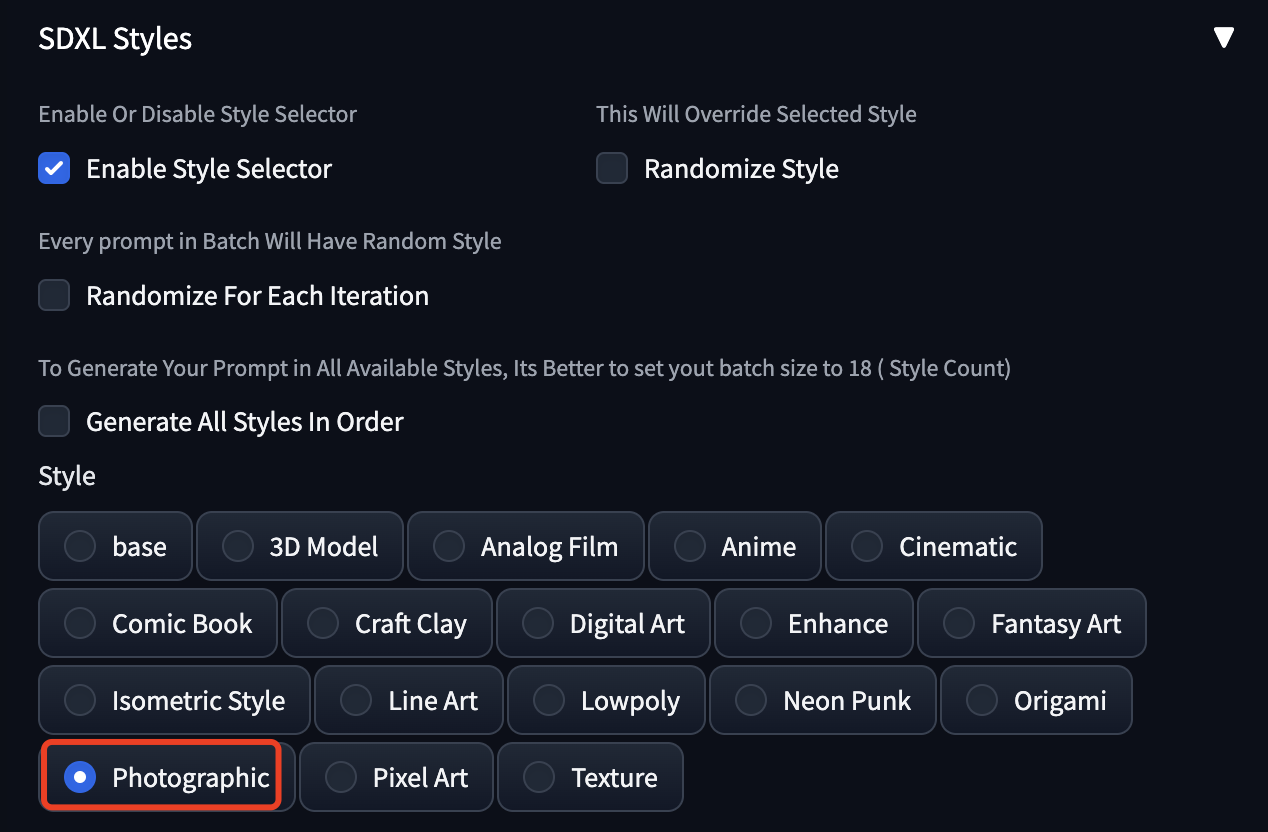
这个镜像自带了一个风格插件,用于实现 Stability AI 官方绘图产品中的绘图风格功能,使用这个插件,可以绘制不同风格的照片,看下边的选项很多,有3D、动漫、照片、数字、线画、插画、像素等很多风格。有了这个确实可以抛弃很多大模型和Lora模型了,所以说SDXL确实进步很大,建议大家试试。
出图之后我们可以在这里把图片发送到“图生图”:

提示词都会带过去,注意这里的基础模型要换成:“sd_xl_refiner_1.0.safetensors”。

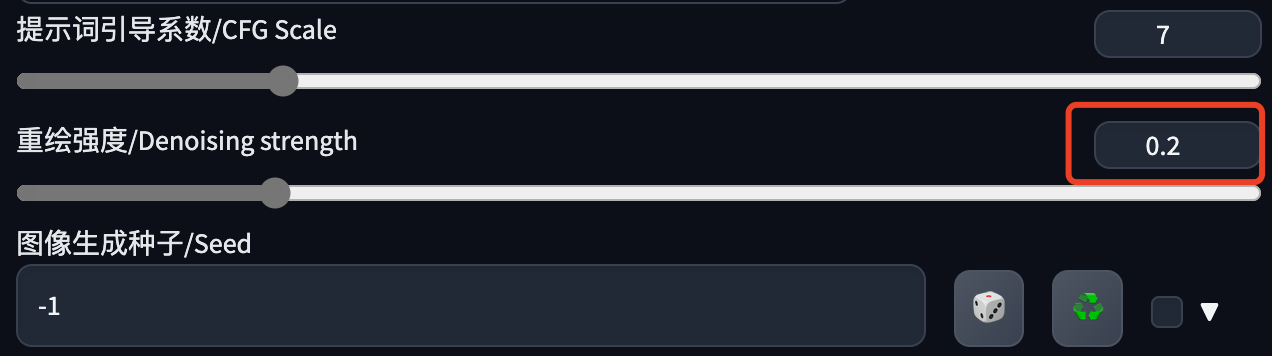
重绘强度建议控制在:0.1-0.3,小了没效果,大了图片会变化过大。
别的参数不用动,然后就可以精修生图了。
不成熟的方法
大家也可以感受到上边的步骤比较啰嗦,所以 SD WebUI 也在开发一个新的方案,类似哩布哩布上的体验,不过目前还是开发版,我这里测试经常出现崩溃的问题,但是有人能够正常运行,所以这里简单给大家说下使用方法,有能力的可以去研究下。
1、下载这个开发版本:https://github.com/AUTOMATIC1111/stable-diffusion-webui/tree/refiner_alt
2、启动后在“设置”-“用户界面”中配置 refiner,如下图所示:
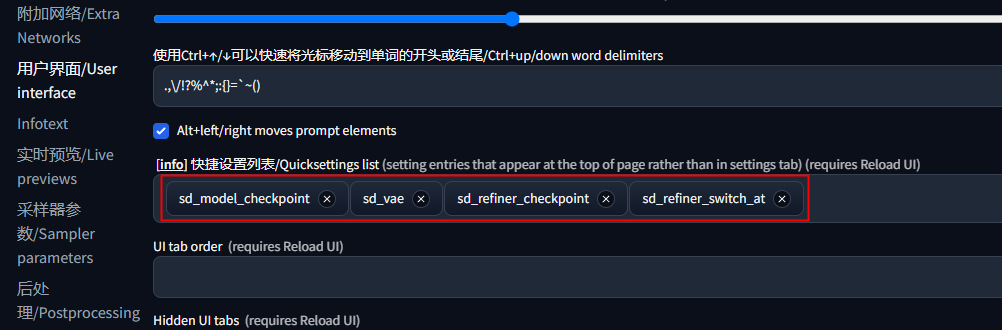
3、进入“文生图”或者“图生图”,在页面顶部可以看到多了两个选项:
Refiner checkpoint :选择SDXL的精修模型。
Refiner switch at:从采样步骤的第几步开始使用精修模型,这是个百分比。比如采样步数是30,这里选择0.8,那就是从 30*0.8=24 开始使用精修模型,在这之前的采样使用基础模型。

可以看到这个方案方便了不少,后续如果我测试没问题了,会将镜像升级到这个新版本。
本地部署体验
我这里没有合适的机器环境,所以没有实际部署,大家可以看这个项目:
https://github.com/vladmandic/automatic
它是从 AUTOMATIC1111/stable-diffusion-webui Fork 过来的,但是针对各种平台做了优化。
具体安装步骤可以参考这篇文章:https://stable-diffusion-art.com/sdxl-model/#Run_SDXL_model_with_SDNext
其它体验方式
Google Colab
这是 Github 上开源的一个 Stable Diffusion XL 1.0 的演示项目,可以在Google Colab上免费运行。如果只是想简单的体验下,访问外网也没有问题,可以试试。
大家打开我分享的这个链接就可以运行。
https://colab.research.google.com/drive/1bBD9VaSTuuw7Xkuw3FRkYCneTDxbnGar?usp=sharing
这里没有启用 Refiner,因为会消耗大量内存,免费规格根本跑不起来。
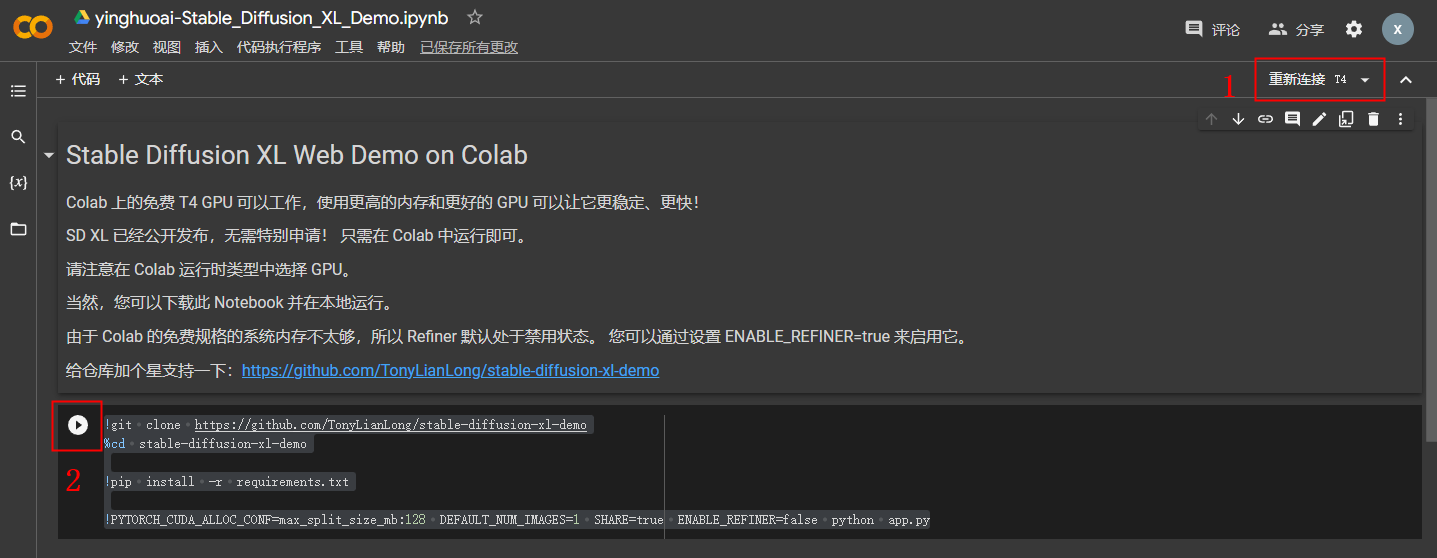
当出现下面这段文字的时候,就说明启动成功了。

点击上图中的这个 public URL,就可以在浏览器中操作了。
不过在使用免费规格时,出过一张图之后,再出图时会出现程序退出的问题,目测也是显存和内存不足导致的,XL需要的资源比较多。
此时可以重启程序,然后再跑下一张,不过也是挺麻烦的。
Kaggle
除了白嫖 Google Colab,我们还可以免费使用 Kaggle,Kaggle 比 Colab 好的是可以使用两个T4,一定程度上可以缓解内存不足的问题。Kaggle 每周可以免费使用30小时,不用的时候停机,停机不会计时。
具体使用方法不说了,网上已经有很多人介绍。
还是上边的 XL Demo 项目,我在Kaggle上也做了一个分享,大家打开下边这个链接:
https://www.kaggle.com/bosimabosima/stable-diffusion-x-1-0-demo
按照下边的步骤操作即可。
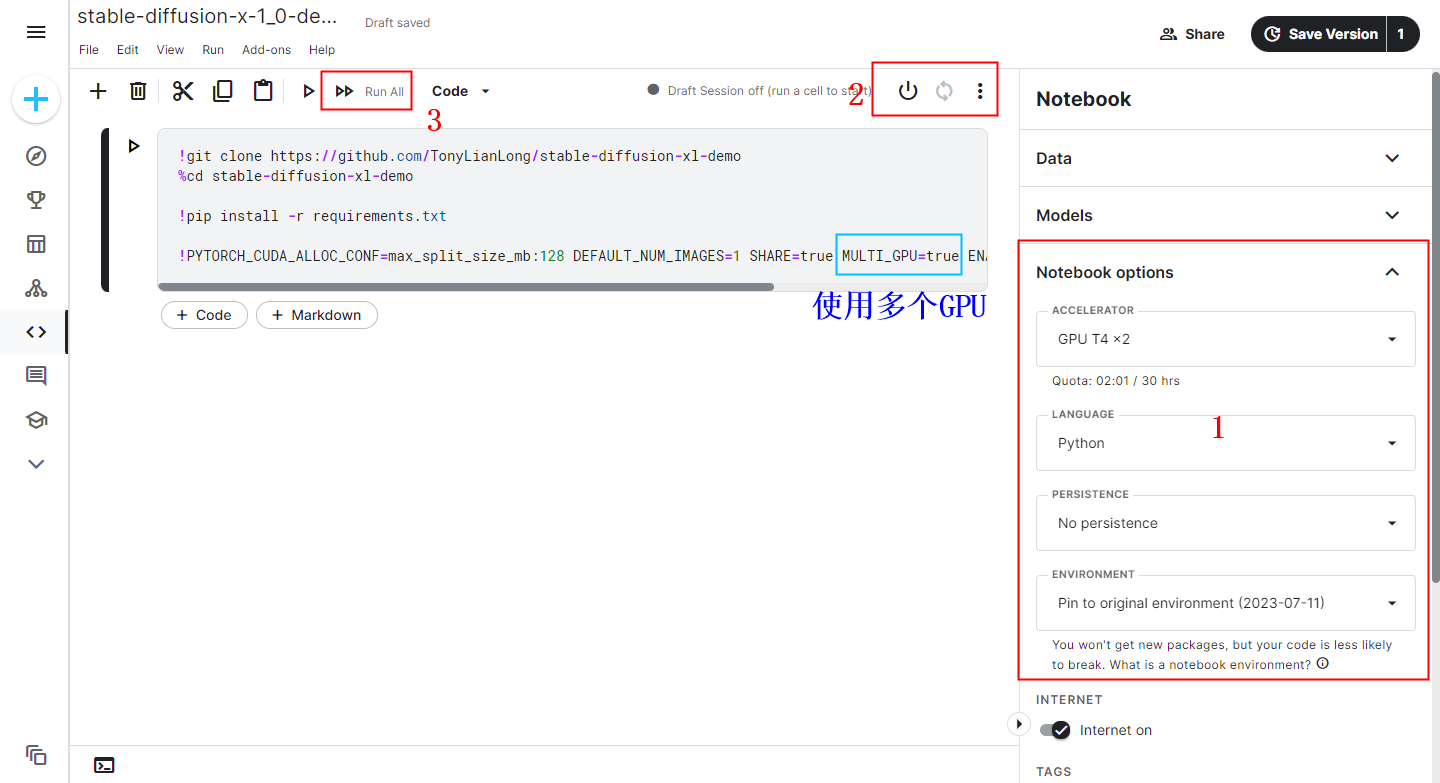
注意这里添加了一个参数:MULTI_GPU=true ,意思就是要使用多个CPU。实测确实可以降低系统内存的压力,连续生成多张图片也没有出现系统崩溃的问题,因为显存够用了就不会去占用系统内存,就不会因为内存无法分配而崩溃。
不过启用 Refiner 还是会导致无法分配的问题,这里 T4 GPU 的内存是 15G,两个就是30G,如果要想流畅的运行SD XL,需要更多内存或显存,这是免费规格提供不了的。
资源下载
如果你下载 SDXL 的大模型或者 StyleSelectorXL 插件不方便,可以通过我整理的资源下载,关/注/公/众\号:萤火遛AI(yinghuo6ai),发送消息:SDXL,即可获得下载地址。
以上就是本文的主要内容了,如有问题欢迎沟通交流。
[AI] Stable Diffusion基础:精准控制之ControlNet
[AI] Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
[AI] Stable Diffusion基础:ControlNet之图像提示(垫图)
[AI] Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
Stable Diffusion基础:精准控制之ControlNet
Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
Stable Diffusion基础:ControlNet之图像提示(垫图)
Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程
Stable Diffusion基础:ControlNet之图片高仿
Stable Diffusion基础:ControlNet之人体姿势控制
SDXL 1.0出图效果直逼Midjourney!手把手教你快速体验!
AI抠图使用指南:Stable Diffusion WebUI Rembg实用技巧