Stable Diffusion基础:ControlNet之图片高仿
今天继续给大家分享AI绘画中 ControlNet 的强大功能,本次的主角是 Reference,它可以将参照图片的风格迁移到新生成的图片中,这句话理解起来有点困难,如果换成高仿,大家应该就明白了吧。我们将通过几个实例来加深体会,比如照片转二次元风格、名画改造、AI减肥成功图片制作、绘本小故事等等。
还有之前看很多文章说,Reference 可以一定程度上代替Lora,真的是这样吗?今天也来一探究竟。
基本使用
我这里有一张提前生成好的美女图片,现在就用她来实测 Reference 的控制效果。

下面开始生成:
首先是选择一个大模型,这里使用的是和上面生成图片相同的模型:realisticVisionV20;
然后我们填写一些简单的提示词,以免出现一些不太方便的图。这里故意没有使用生成参考图片时的提示词,因为提示词会影响出图效果,就看不出来 Reference 的复刻效果了。
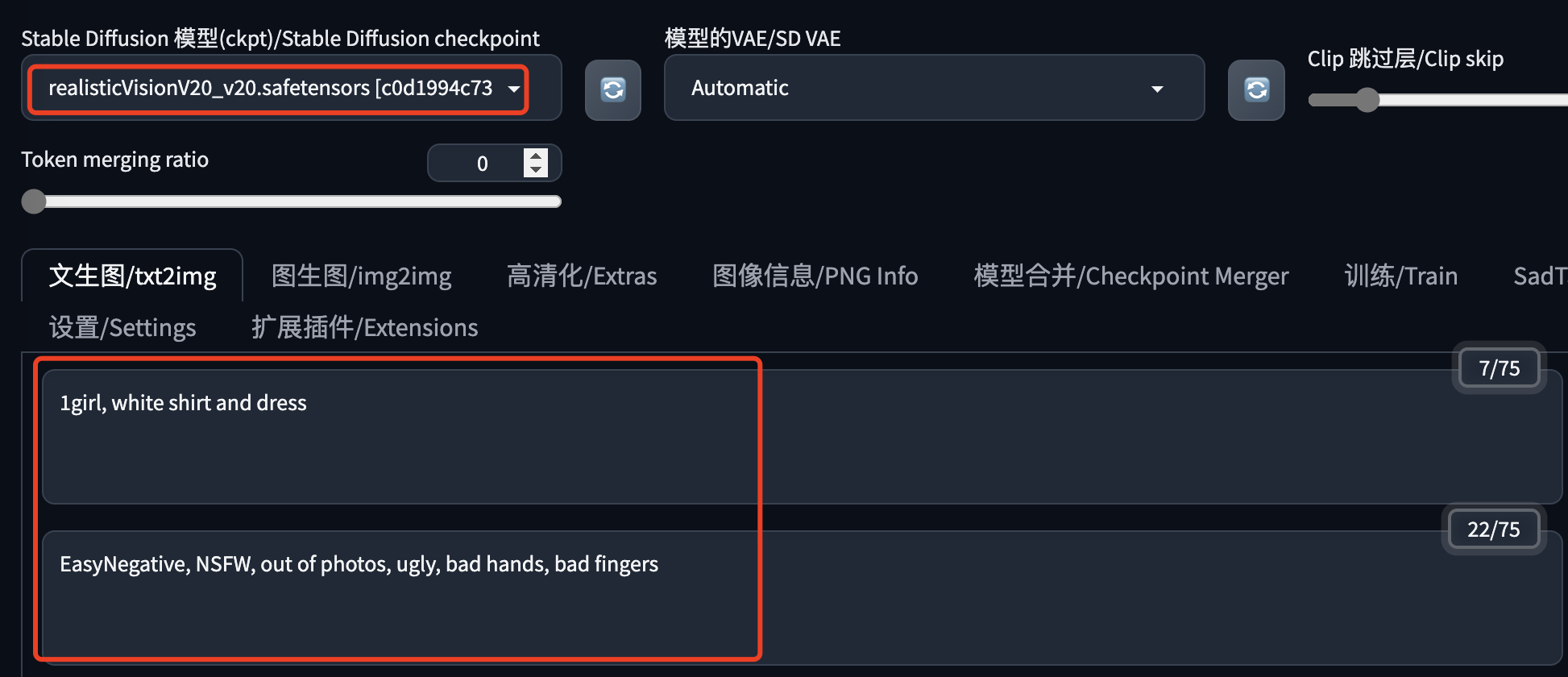
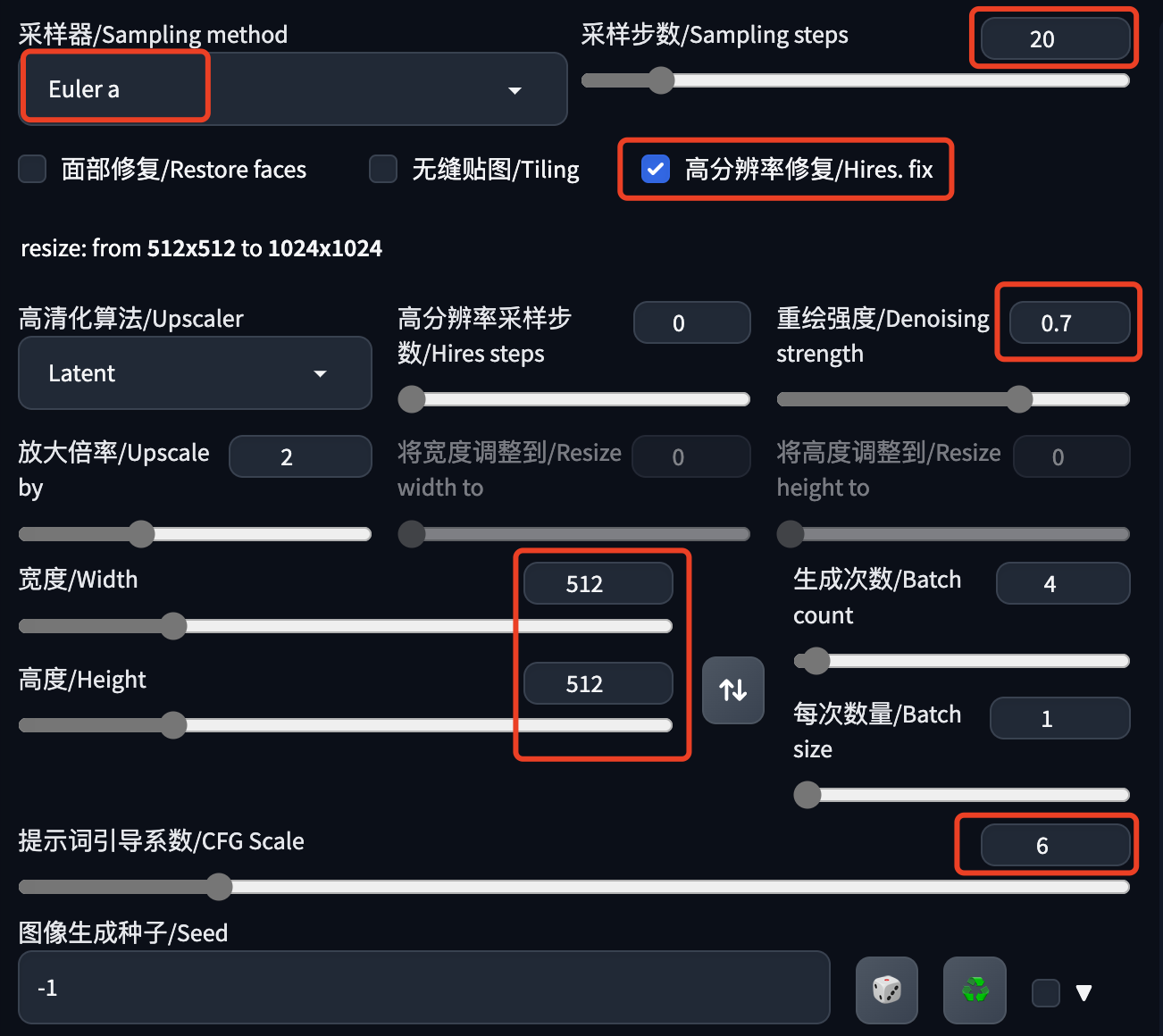
这是我的一些模型生成参数,大家可以参考,没必要完全按照这个来。
最最重要的就是 ControlNet 的设置,如下图所示:
- 上传参考图片
- 启用 ControlNet
- 勾选完美匹配像素
- 选择 Reference
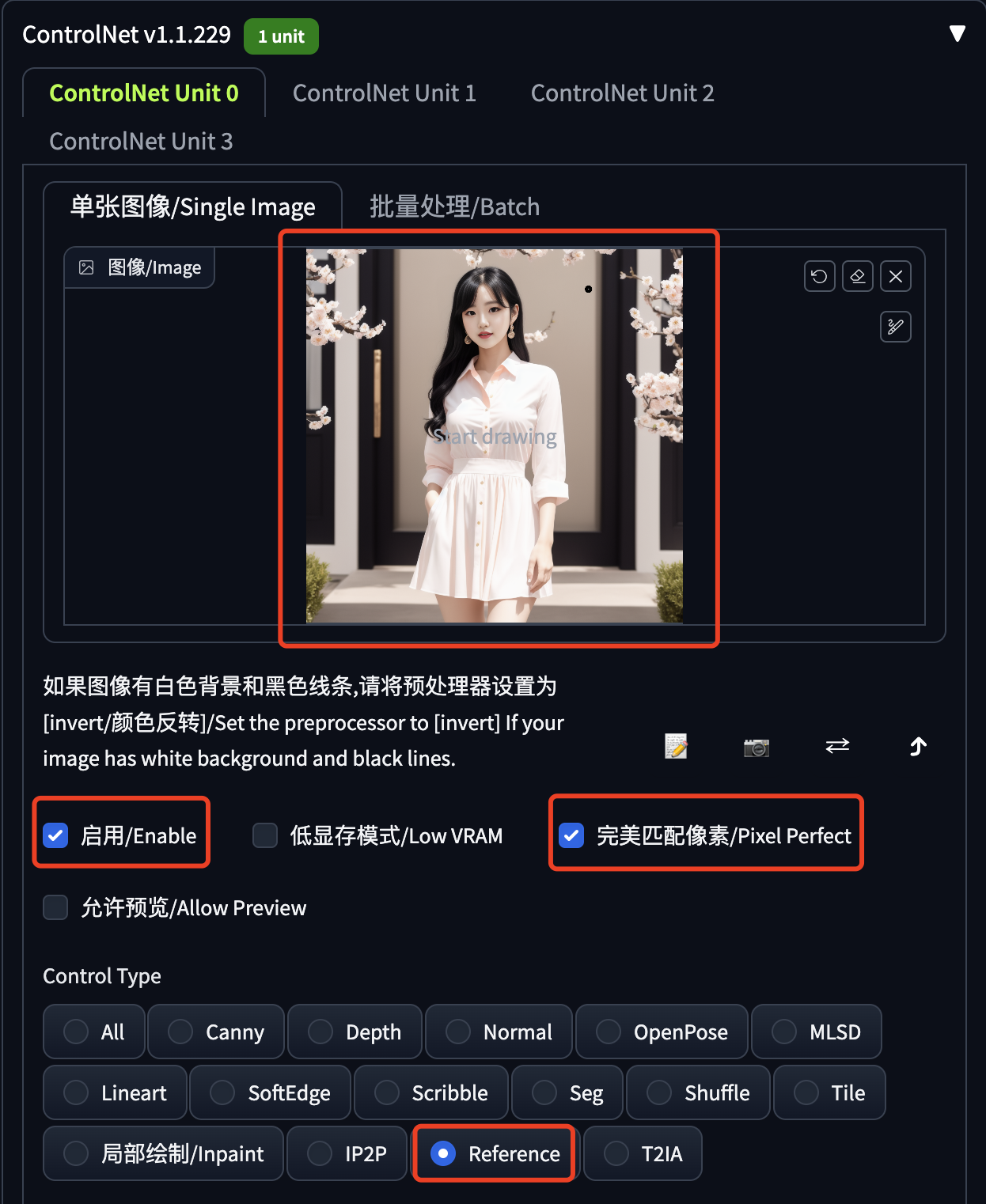
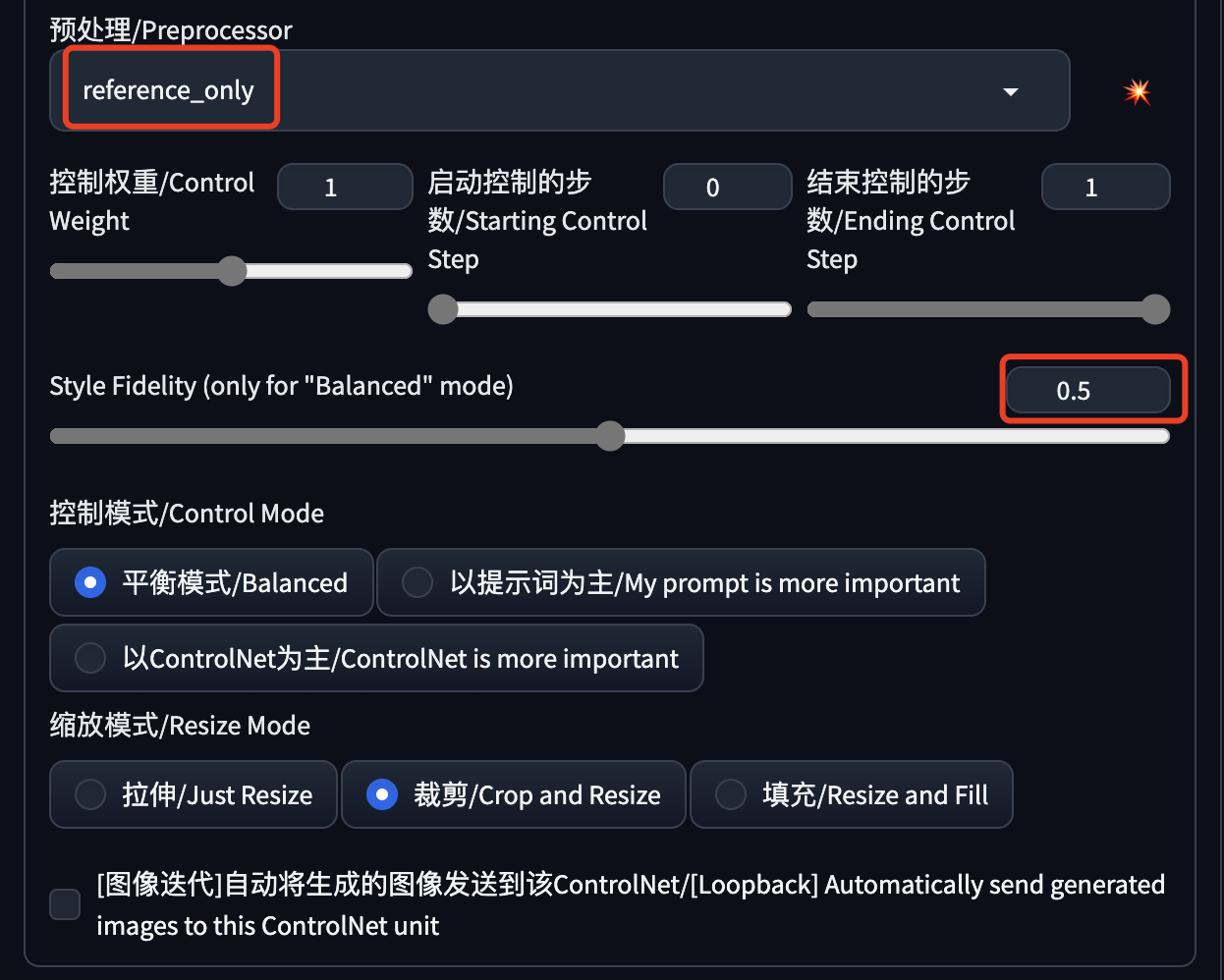
注意这个 ControlNet 只有一个预处理器,它可以从参考图中提取图片的特征信息,用于生成控制。
Reference 还有一个 Style Fidelity 参数,翻译过来就是风格忠实度,越小越接近使用的大模型的风格,越大越接近参考图的风格,但是越大可能出现图片崩坏的情况,0.5是个平衡值。
然后就可以生图了,看一下效果:

以我个人的眼光,只能说:人物的形态、整体构图是复制出来了,但是气质还是差那么一点的。
局部绘制
很多分享 Reference 技术的文章还提到,Reference 可以起到一定的 Inpaint 效果,那么这里也来看下效果如何。这里的局部重绘是通过提示词发生作用的,下面是几个例子:
裙子变成黑色:1girl, white shirt, ((black skirt)),提示词权重要高一些,否则不容易扭转过来。人物姿态和背景都没啥大变化,裙子也变成了黑色,只是有一张用力过猛,上衣颜色也变了。

黑发变成金色:1girl, white shirt and dress, ((golden hair))。人物姿态和背景都没啥大变化,头发变成金色的了,人脸也没变成外国人。

把背景换成公园:1girl, white shirt and dress, ((the background is park))。背景更换成功,同时人物姿态和衣服颜色都没啥大变化。

不同模型
上边的参考图片和生成图片使用的是同一个大模型,测试结果难免会有说服力不够的问题,下图是我使用三个模型做的对比测试,每个模型使用 Reference 生成两张图片。
提示词还是这个:1girl, white shirt and dress, 其它参数都保持不变。

可以看到,人物的形态、背景、色彩搭配等都被迁移到了新生成的图片中,当然这些图片也还会受到基础模型的很大影响,渲染的笔触、人物的五官都受到模型的紧密约束。
到这一步,你能说 Reference 是 Lora 吗?它能代替 Lora 吗?我认为它们是有很大的不同的。
控制参数
Reference还有一些控制参数,这里给大家看下效果。
为了方便演示,我这里专门生成了一张连环画风格的图片作为参考图:

然后生成图片的大模型选择的是二次元模型 AnythingV5。
Style Fidelity

值为 1 的效果:色彩更偏重参考图。

值为 0 的效果:色彩更偏重模型。

预处理器
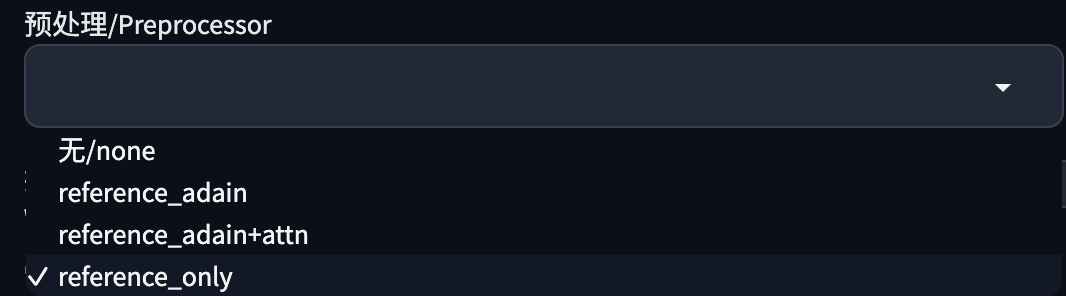
这里有三个预处理器:
- Reference only:生成与参考图类似的风格和脸部。
- Reference adain:使用 AdaIN 风格迁移算法,结果可能偏离参考图;
- Reference adain+attn:综合 only 和 adain 方法。
Reference only 我们已经看过了,分别看下另外两个的效果。
Reference adain:确实更接近模型,颜色和脸型的变化特别明显,更加偏重 Anything 的二次元风格。

Reference adain+attn:介于模型风格和参考图风格之间。

用途示例
风格转绘
比如各大短视频平台比较流行的照片转动漫风格,可以在“图生图”中上传一张真实照片,然后使用动漫风格的大模型加上 Reference 进行重绘。下图的效果,提示词只要一个简单的:1girl,重绘强度控制在0.4以下即可。

名画改造
这是利用了 Reference 的局部重绘能力。在“图生图”中使用如下提示词:
女人和猫咪:A woman and a cat
背景改长城:A woman, the background is Badaling Great Wall
注意重绘幅度调整到0.4-0.6。

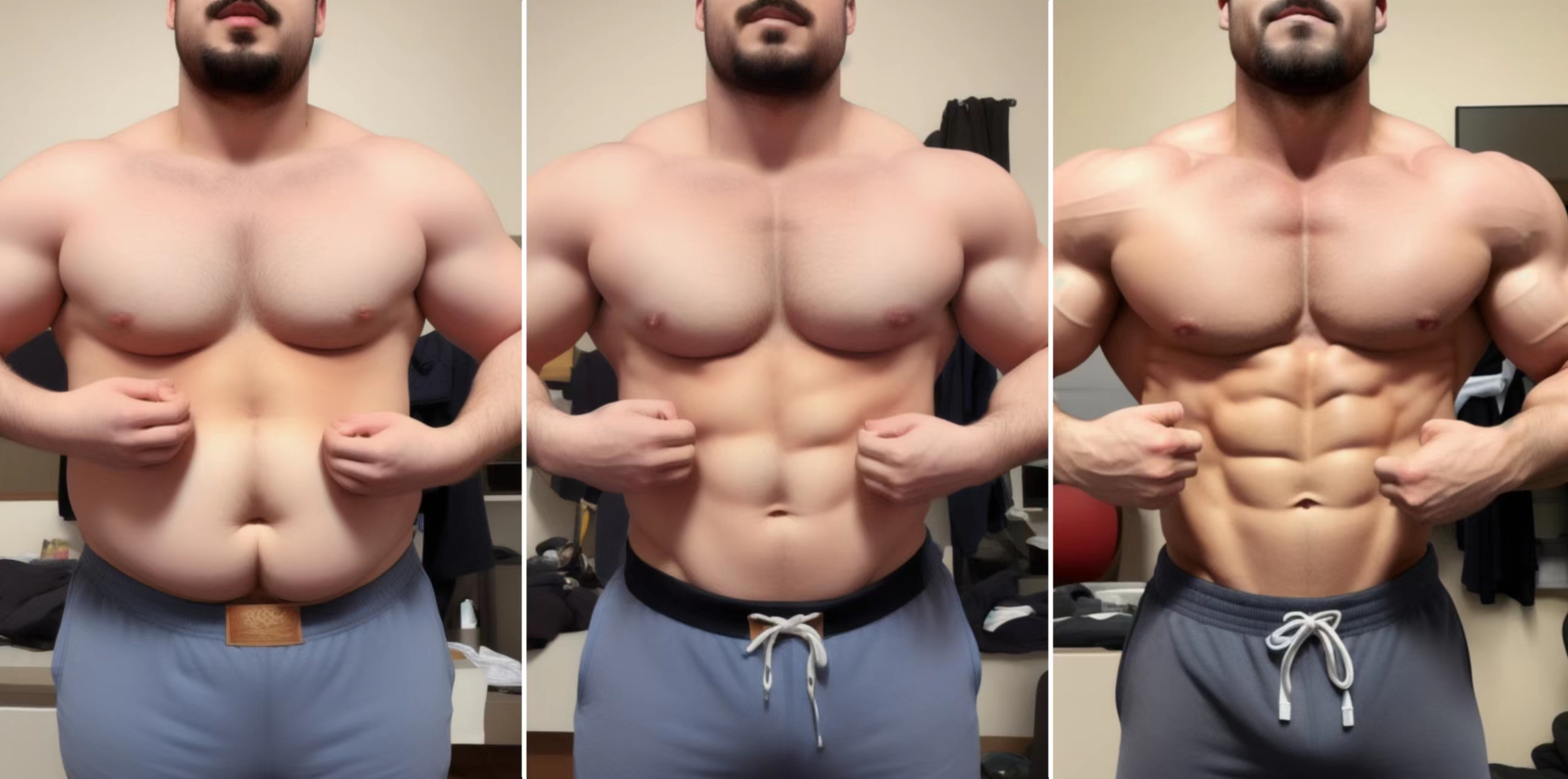
减肥成功
一个AI减肥成功的故事,还是利用了 Reference 的局部重绘能力。
大模型使用realisticVisionV20_v20,参数参考:
A strong man lifts up his shirt, eight-pack abs, strong chest muscles, and biceps.
Negative prompt: EasyNegative
Steps: 30, Sampler: DPM++ 2M SDE Karras, CFG scale: 7, Seed: 1734015608, Size: 512x768, Model hash: c0d1994c73, Model: realisticVisionV20_v20, Denoising strength: 0.75, Clip skip: 2, Style Selector Enabled: True, Style Selector Randomize: False, Style Selector Style: base, ControlNet 0: "preprocessor: reference_adain+attn, model: None, weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: My prompt is more important, preprocessor params: (-1, 0.5, -1)", TI hashes: "EasyNegative: c74b4e810b03", Version: v1.5.1
如果感觉脸不像,可以使用 roop 插件处理下,使用方法参见我另一篇教程:https://mp.weixin.qq.com/s/jXNNvTZKYaYxJ7fsmUpCzQ
绘本小故事
故事情节
小女孩走在放学回家的路上,步履匆匆;
她在路边发现了一只受伤的狗子,表情痛苦,怎么办呢;
小女孩一咬牙,抱着狗子来到了医院;
狗子得到了救治有点开心,女孩花光了钱有点不高兴;
小女孩和狗子欢快的走在回家的路上,因为他们成了好朋友。
狗子从此有了一个家。
制作方法:
提前生成一张女孩的图片,然后使用 Reference 加不同的提示词生成不同的图片。
这里使用的大模型是 toonyou_beta3。

资源下载
本文使用的模型、插件,生成的图片,都已经上传到了我整理的SD绘画资源中,后续也会持续更新,如有需要,请关注公众号:萤火遛AI(yinghuo6ai),发消息:SD,即可获取下载地址。
以上就是本文的主要内容了,如有问题,欢迎给我留言沟通交流。
如果你还没有使用过Stable Diffusion WebUI,可以先看这几篇文章,了解下如何使用:
手把手教你在本机安装Stable Diffusion秋叶整合包
手把手教你在云环境炼丹(部署Stable Diffusion WebUI)
SDXL 1.0出图效果直逼Midjourney!手把手教你快速体验!
[AI] Stable Diffusion基础:精准控制之ControlNet
[AI] Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
[AI] Stable Diffusion基础:ControlNet之图像提示(垫图)
[AI] Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
Stable Diffusion基础:精准控制之ControlNet
Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
Stable Diffusion基础:ControlNet之图像提示(垫图)
Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程
Stable Diffusion基础:ControlNet之图片高仿
Stable Diffusion基础:ControlNet之人体姿势控制
SDXL 1.0出图效果直逼Midjourney!手把手教你快速体验!
AI抠图使用指南:Stable Diffusion WebUI Rembg实用技巧