手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程

很多同学都想要自己的专属AI模型,但是大模型的训练比较费时费力,不太适合普通用户玩。AI开发者们也意识到了这个问题,所以就产生了微调模型,LoRA就是其中的一种。在AI绘画领域,只需要少量的一些图片,就可以训练出一个专属风格的LoRA模型,比如某人的脸、某个姿势、某种画风、某种物体,等等。
训练模型经常被大家戏称为“炼丹”,这个词既给我们带来了美好的期待,也体现了模型创作过程的不易。如同炼丹需要精心呵护,AI模型的训练也需要耐心和细致。然而,即使付出了辛勤的努力,最终的结果也未必能如人意。这是大家需要做好的心理准备。
LoRA的原理网上已经有很多介绍,我就不说了。本文专门介绍在云环境怎么训练LoRA模型,所谓云环境就是租用云服务器,而不是在本地电脑上,这特别适合想一展身手但是手里又没有一块好显卡的同学。
这里的云环境选择我经常使用的AutoDL:https://www.autodl.com , 关于AutoDL的使用方法,本文只围绕训练LoRA模型做一些简单的介绍,想了解更多的同学请看我写的另一篇文章:手把手教你在云环境部署 Stable Diffusion WebUI 。
本文将使用 kohya_ss 这个开源项目来训练LoRA模型, 下面正式开始。
云环境
AutoDL上需要先充值然后才能租用服务器,可以先来2块钱的,以便完成本次训练。
服务器
简单说下,计费方式选择“按量计费”,地区选择“内蒙A区”,GPU型号选择“RTX A5000”,GPU数量选择“1”,然后选择1个有空闲GPU的主机。
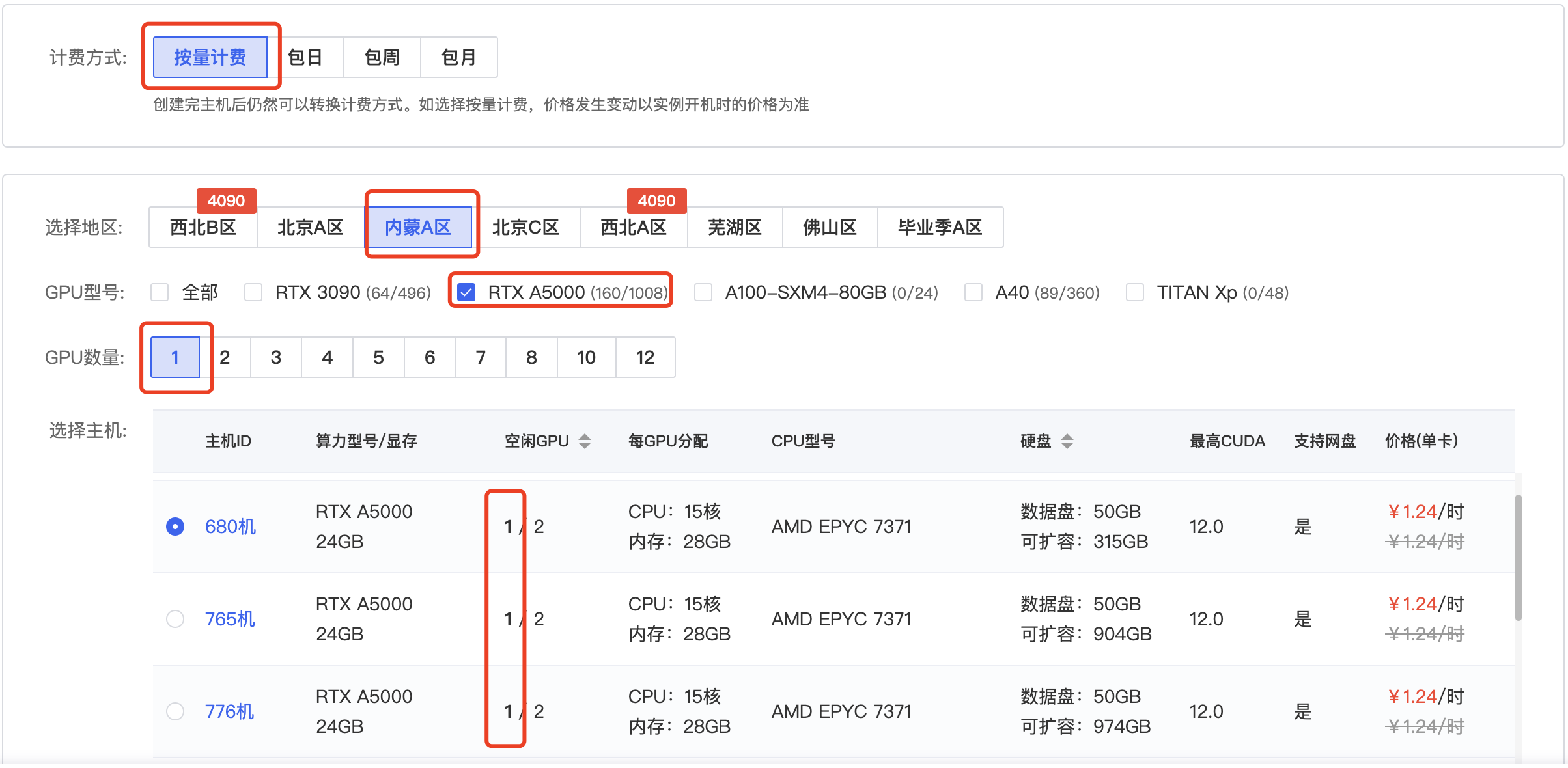
镜像这里选择“社区镜像”,输入“yinghuoai-kohya”,在弹出的菜单中选择我发布的这个镜像。
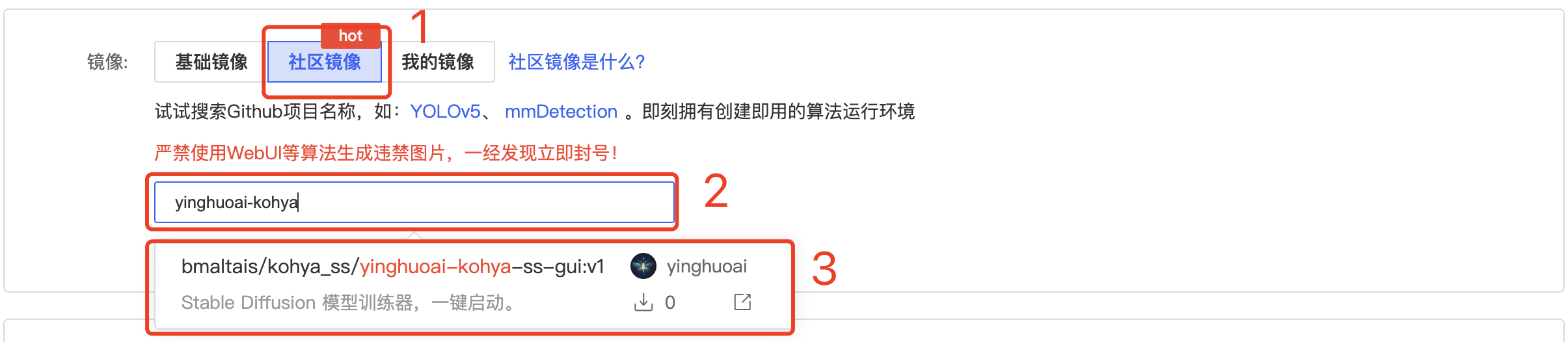
然后点击“立即创建”就可以了。
在 AutoDL 控制台等待服务器实例开机,开机成功后,在快捷工具这里可以看到一些操作项,点击其中的“JupyterLab”。

在 JupyterLab 中点击笔记本上方的双箭头按钮,它会进行一些初始化操作,并启动 kohya_ss,待看到“Running on local URL”的提示后,就说明启动成功了。
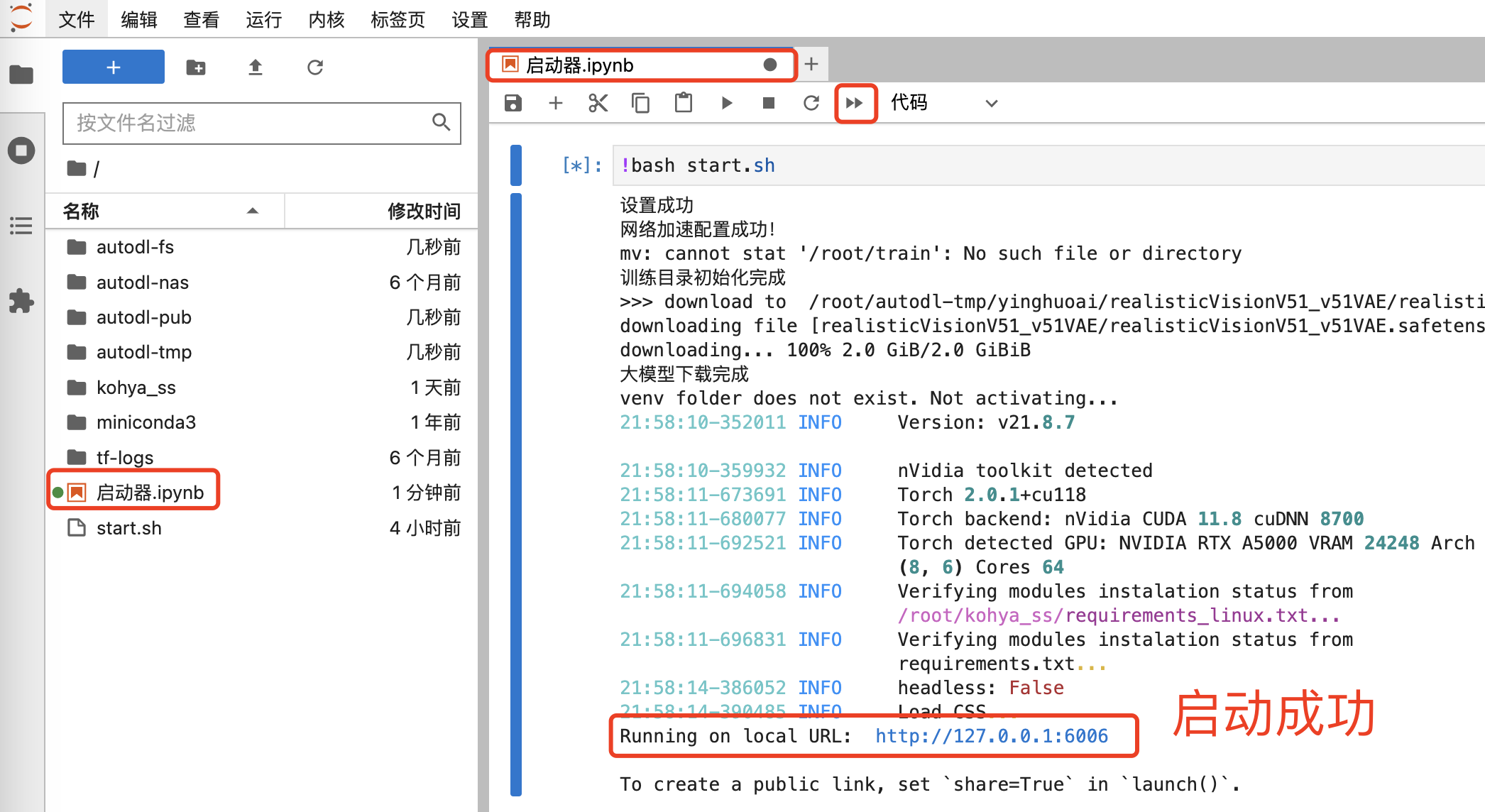
然后回到 AutoDL 控制台,点击快捷工具中的“自定义服务”,即可启动 kohya_ss 的Web界面。

训练目录
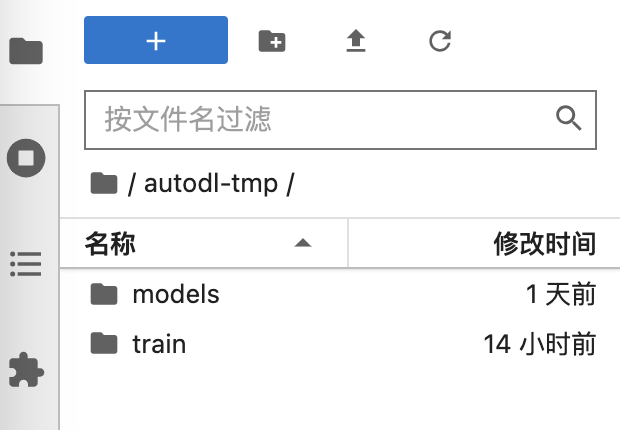
为了有效的管理模型训练,我在镜像中创建了几个目录,可以通过“JupyterLab”查看,它们都在 /root/autodl-tmp 下边,autodl-tmp 挂载的是 AutoDL 的数据盘,可以节省宝贵的系统盘空间。
- /root/autodl-tmp/models:SD大模型目录,训练Lora模型时需要基于某个大模型。
- /root/autodl-tmp/train:训练数据的目录,包括输入的图片、训练的参数、输出的Lora模型等,我们将在这个目录下创建不同的训练项目目录。
实际效果如下图所示:
快速体验
我在镜像中内置了一份训练数据和训练配置,可以让大家快速体验 Lora 炼丹。
通过 AutoDL 的自定义服务启动页面后,依次点击“LoRA”->“Training”。
- 在“Configuration file”这里输入我提前预置好的训练配置文件地址:/root/autodl-tmp/train/dudu/config.json ;
- 然后点击“Load”加载训练参数;
- 最后点击“Start training”开始训练。
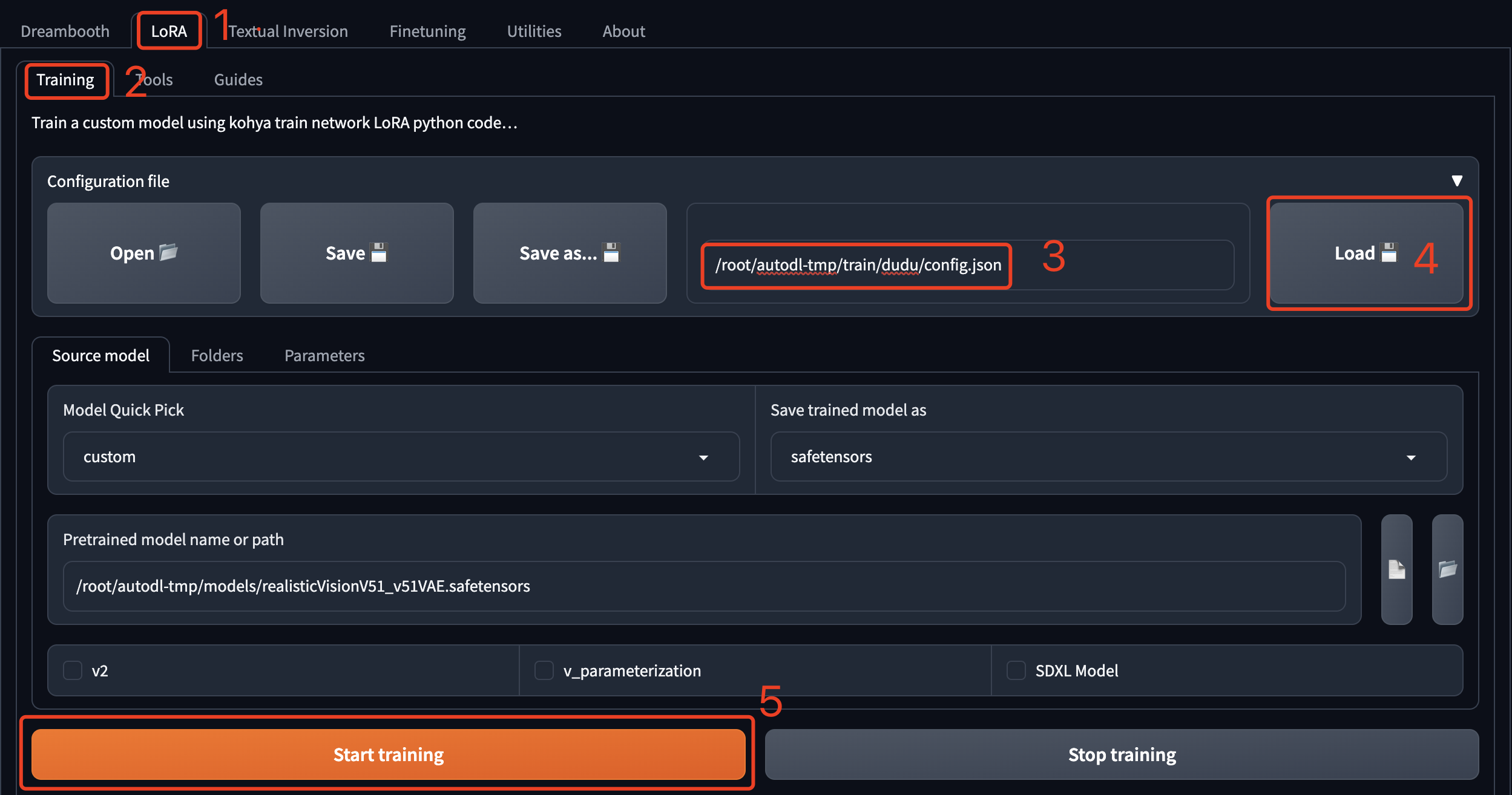
训练的进度需要去 JupterLab 中查看,大约需要8分钟,当看到 steps 显示 100%的时候就说明训练完成了,模型已经保存到目录:/root/autodl-tmp/train/dudu/model

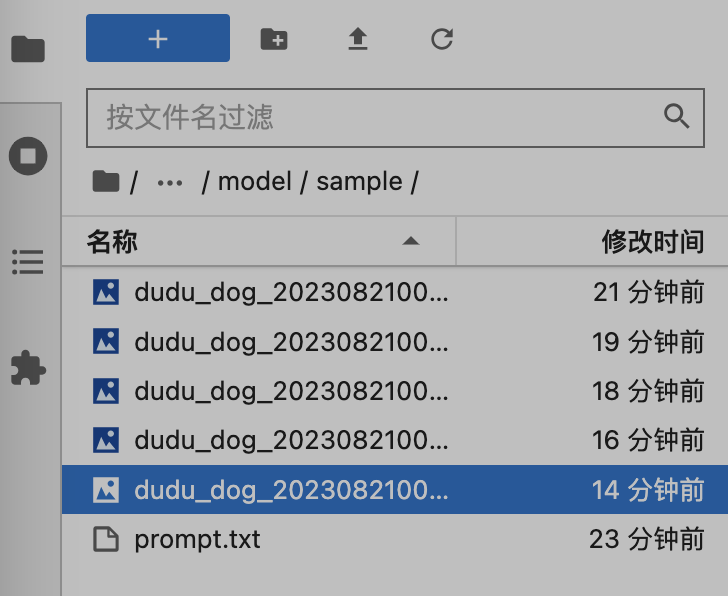
训练过程中会生成几张采样图片,保存在 /root/autodl-tmp/train/dudu/model/sample ,可以打开看看训练的效果:
为了实际体验,需要把模型文件先下载到本地,然后再上传到 Stable Diffusion WebUI,使用文生图生成图片,参考参数:
- 大模型:realisticVisionV51_v51VAE,其它真实模型也可以试试。
- 提示词:masterpiece, best quality, 1dog, solo, sitting, looking at viewer, outdoor, the background is egyptian pyramids,tall pyramids <lora:dudu_log:0.8>
- 反向提示词:low quality, worst quality, harness, tree, bad anatomy,bad composition, poor, low effort
- 图片尺寸:768*768
注意:如果你要重新训练这个项目,需要先删除 model 目录下的内容,然后再重新开始训练。
快速体验只能让大家简要领略炼丹的魅力。然而,要炼就一颗完美的丹药,还需备足图片素材、洞悉工具参数设置,以及不断测试优化模型。接下来,我将为大家详细解析如何步步为营,精心打造你的LoRA模型。
准备
主要就是准备好要训练的图片,以及为图片生成提示词。然后才能把它们送进丹炉进行炼制。
挑选图片
训练LoRA模型到底需要几张图片?我没找到具体要求,建议至少10张以上,并且要求图片清晰有质感,如果是针对某种个体的,拍摄目标的角度要多样,这样才可能训练出比较好的模型。
如果你手头没有合适的图片,可以自己拍摄,也可以去百度图片等图片网站找高清大图。
网上的教程大多是训练美女脸的,估计大家也都看烦了,所以我选择了一个狗子的图片进行训练,它的名字叫dudu,样子大概是下图这样的。我准备的图片数量有20张,已经内置到我发布的 AutoDL 镜像中。

裁切图片
图片需要处理成一样的尺寸,尺寸可以是 512*512、512*768,512*640,都是64的倍数。显存低的可以用 512,显存高的可以用 768。这里给大家分享一个裁切图片的网站:https://www.birme.net/ ,操作方式如下图所示:
- 左边选择本地要裁切的图片。
- 右边是裁切设置,可以设置裁切的尺寸等。
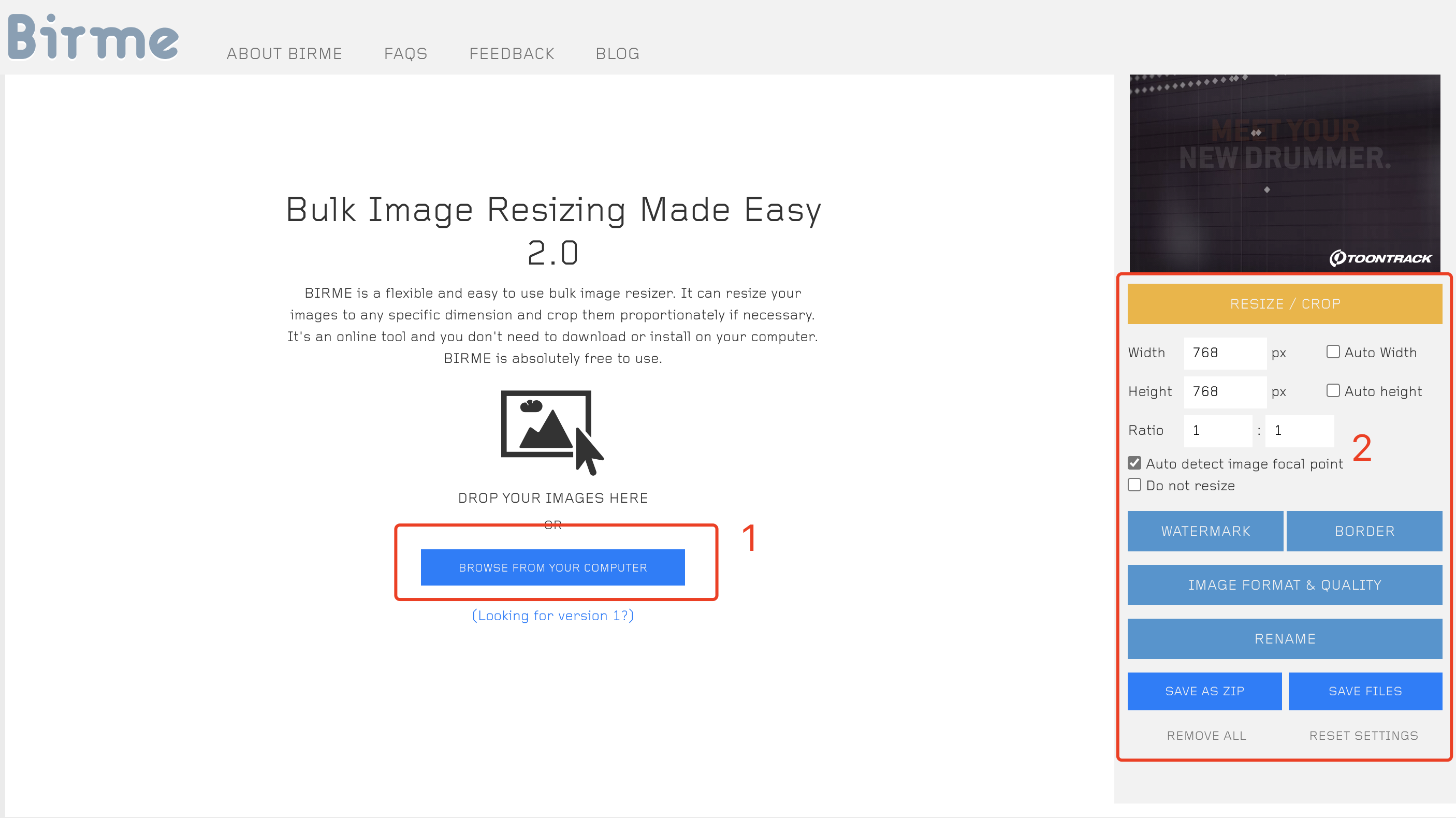
注意 RENAME 可以让输出的图片名称更加有序,方便训练程序使用,xxx 代表三位数字,下边的 starting number 代表从哪个数字开始排序。
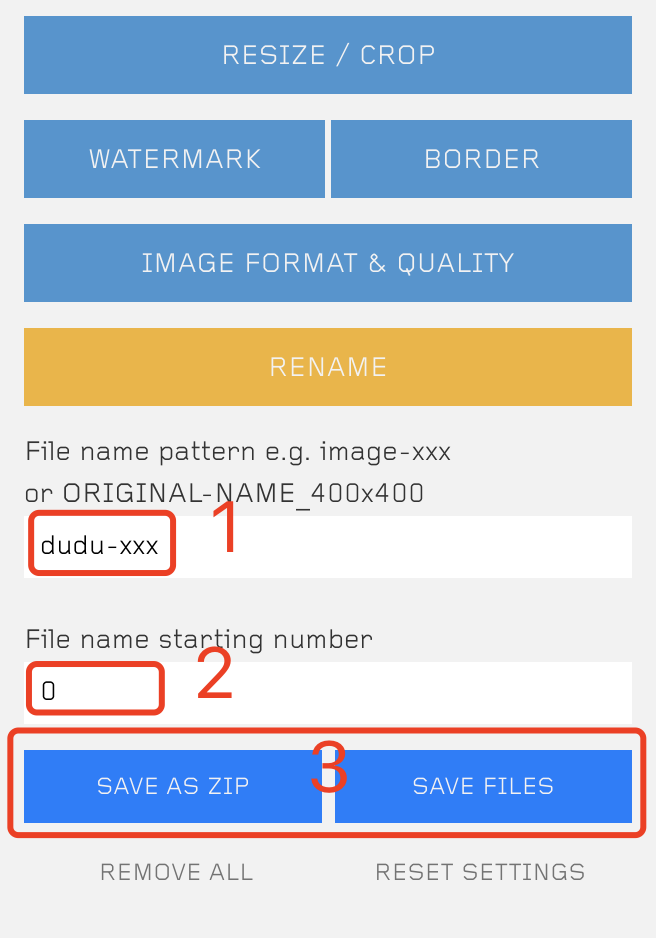
部署图片
图片处理成功后,需要放到特定的目录中。
我们先在 /root/autodl-tmp/train 下创建一个项目目录,我这里就用狗子的名字:dudu,然后在这个目录下再创建一个 img 目录,用于放置处理好的图片,不过图片还不能直接放到 img 下,还需要创建一个子目录:100_dudu,这个目录的名字是有讲究的,前边的100代表每张图片需要学习100次,后边的 dudu 就是图片的主题名字。
这里的学习次数没有固定的标准,真实图片建议50-100,二次元15-30。如果最终训练出的模型出现过拟合的问题,比如生图提示词写了蓝眼睛但是生成的都是黑眼睛,可以降低下学习次数试试。
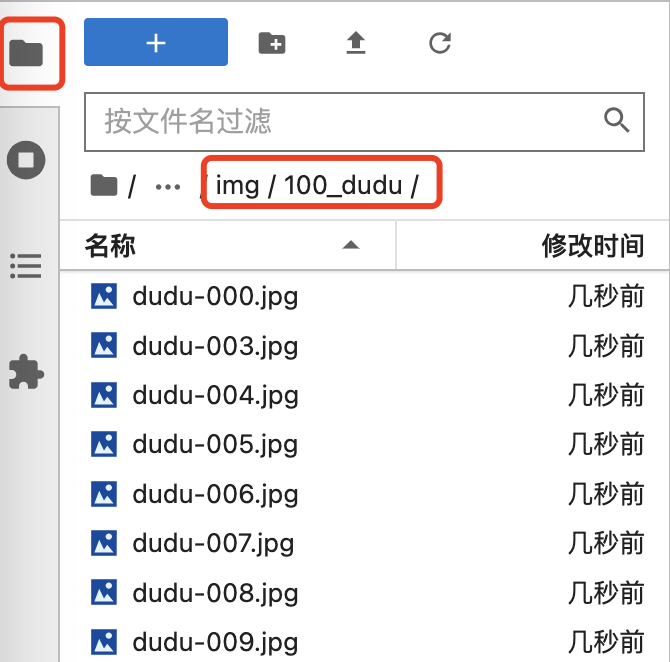
把裁切好的图片上传到 /root/autodl-tmp/train/dudu/img/100_dudu 这个目录,如下图所示:
图片打标
所谓打标就是给图片编写提示词,一般先使用提示词反推工具生成提示词,然后再根据实际情况修改生成的提示词。
启动 kohya_ss 后,进入打开的 Web 页面,依次进入“Utilities”->“Captioning”->"BLIP Captioning"。
“Image folder to caption”中输入待打标的图片目录,我这里就是:/root/autodl-tmp/train/dudu/img/100_dudu。
“Caption file extension”是生成的提示词文件的后缀名。
“Prefix to add to BLIP caption”是添加到生成提示词中的固定前缀,训练中如果使用了这些前缀,生成图片时就可以使用这些前缀比较方便的触发Lora模型,但是根据经验也不能保证一定触发。后边还有一个参数“Postfix to add BLIP caption”,这个是固定后缀。前缀在处理图片时的优先级更高一些。
其它参数都用默认就好了,有兴趣的可以研究下,我这里就不展开了。
最后点击“Caption images”。
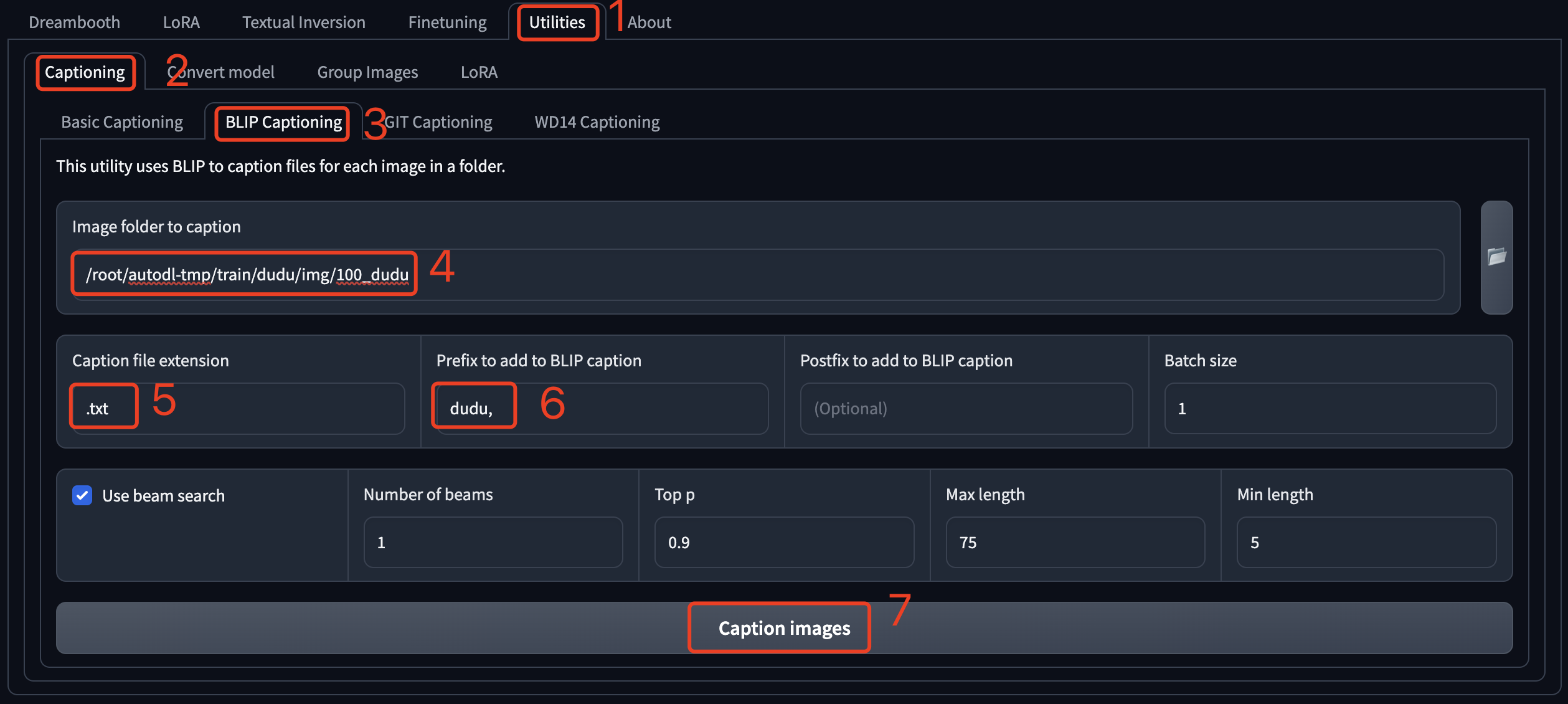
注意这个工具的页面中都没有进度跟踪,需要到 shell 或者控制台界面查看,看到 100% 的进度条,以及“captioning done”的提示就说明打标完成了。
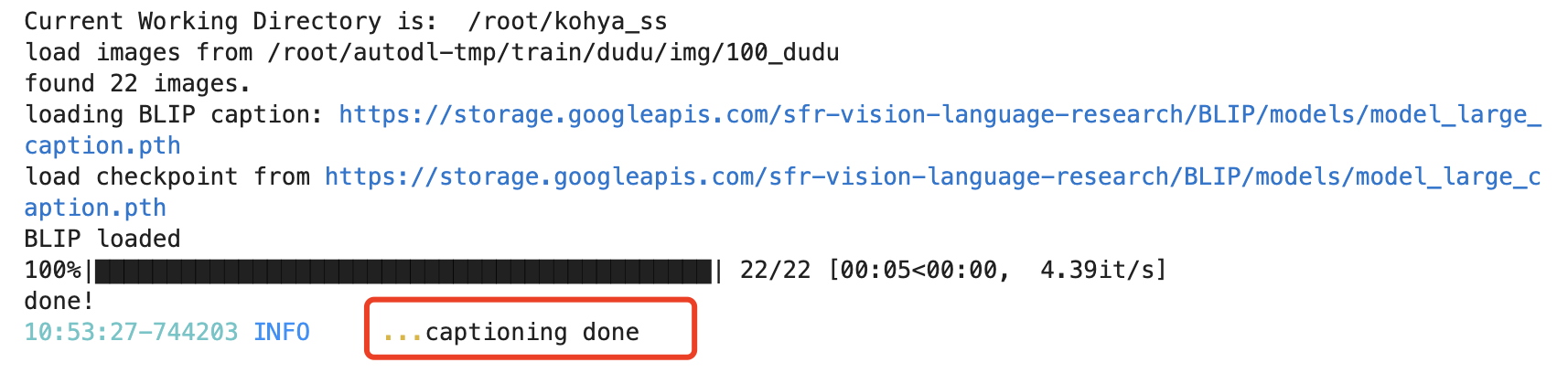
此时我们进入待训练的图片目录,就可以看到这些打标文件了。可以看到,每张图片都生成了对应的打标文件。
我们可以双击打开这些 txt 文件,查看其中的内容;如果感觉写的不好,可以修改它。
生成的提示词一般多多少都会有些问题。
- 对于画风类型的Lora,可以保留全部生成的标签,但是在训练时要多训练几轮,训练时间可能比较长。
- 对于特定角色的Lora,如果我们想保留某个特征作为角色的自带特征,就把对应的标签删除,比如长头发,这样Lora中就会保存长头发作为角色的特征。不过这也是有缺点的,可能导致生成图片时过拟合:提示词不生效,比如输入短发生成的还是长发,严重的还可能导致画面崩坏、模糊不清。
修改提示词是个大工程,这里为了尽快演示,就不修改提示词了。
另外在这个工具中,我们可以看到,除了 BLIP,还有三个给图片打标的方法,不过我都没有跑成功,有兴趣的可以一起研究下。
如果你不使用 kohya_ss 自带的打标工具,也是完全可以的,比如 SD WebUI 的“训练”功能中也可以裁切图片并反推提示词,只是需要手动上传打标文件到这里的训练目录中。这里再推荐一个提示词编辑工具:https://github.com/starik222/BooruDatasetTagManager,有兴趣的可以去试试。
训练
参数设置
训练模型的参数很多,还会涉及到深度学习的一些概念,之前没接触过的同学可能会感觉头疼,不过没关系,我会尽量把主要的参数说清楚。
kohya_ss 启动后,依次进入“LoRA”->“Training”。
Source Model
设置训练使用的 Stable Diffusion 大模型,“Model Quic Pick”这里可以选择一些 SD 的基础大模型,训练的时候会先去 HuggingFace 下载,不过我实际测试跑不同,所以这里选择 custom,然后自己上传一个模型,因为训练图片是真实世界的狗子,所以这里使用了realisticVisionV51(使用AutoDL镜像的同学不用再上传,已经内置了),这是一个真实视觉模型。
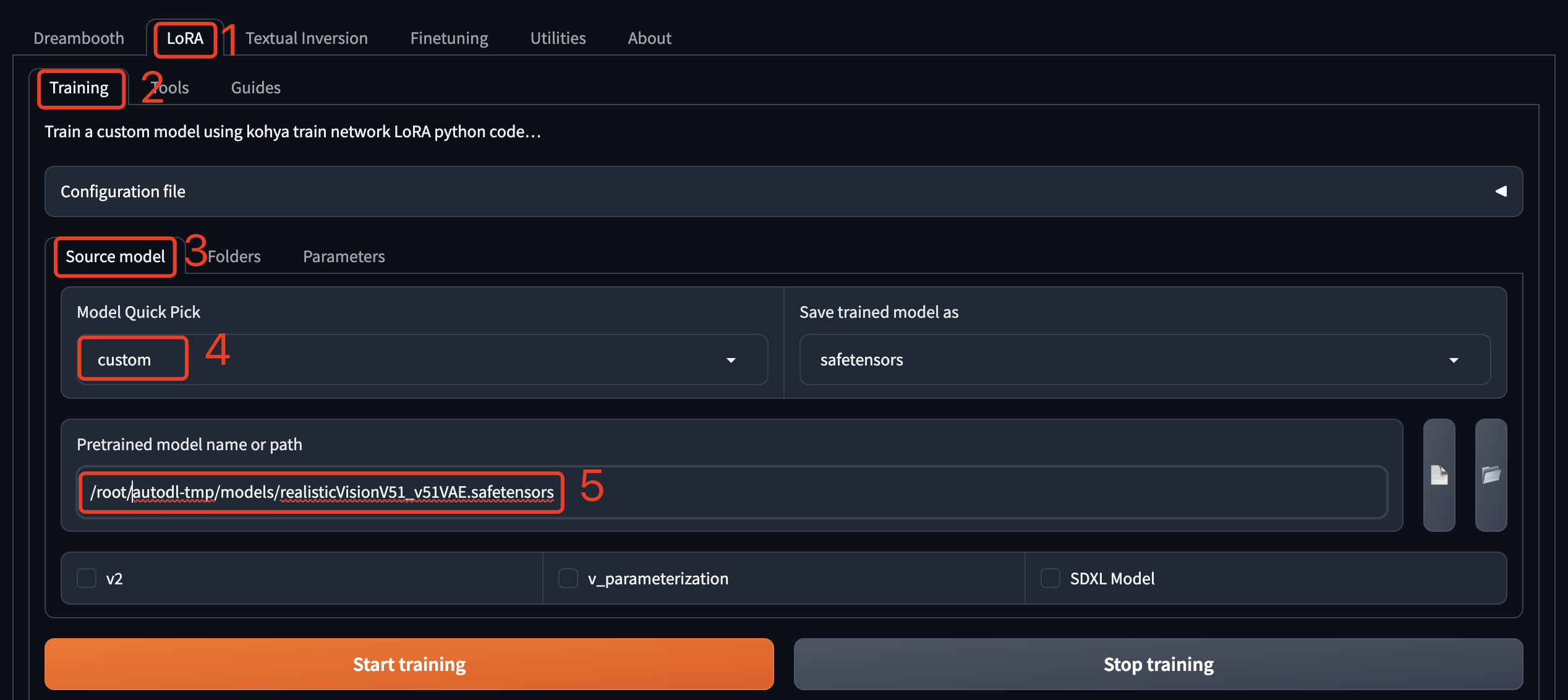
Folders
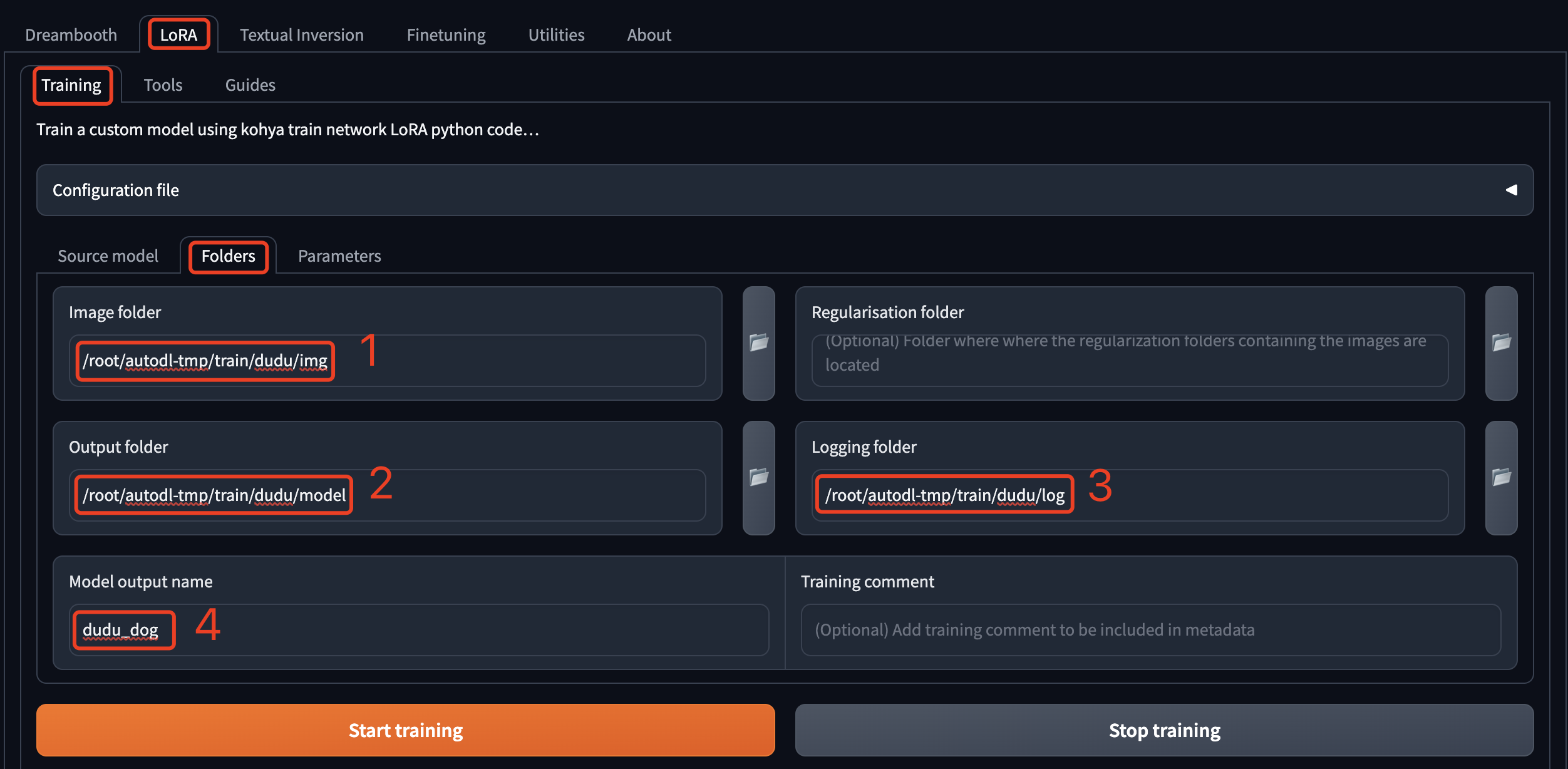
设置训练模型时的输入输出目录。
- Image folder 是训练数据集的目录,也就是原图片的目录,注意只到 img 这一级,不是直接存放图片的目录,这里的完整路径是:/root/autodl-tmp/train/dudu/img 。
- Output folder 是训练出的Lora模型保存的目录,训练过程中的采样图片也保存在这个目录下,和 Image folder 使用同一个上级目录就行了,这里的完整路径是:/root/autodl-tmp/train/dudu/model 。
- Logging folder 顾名思义,就是训练的日志目录,和 Image folder 使用同一个上级目录就行了,这里的完整路径是:/root/autodl-tmp/train/dudu/log 。
- Model output name 是训练出的Lora模型的文件名前缀。
Parameters
进入到真正的参数设置环节了,前边只是些开胃小菜。
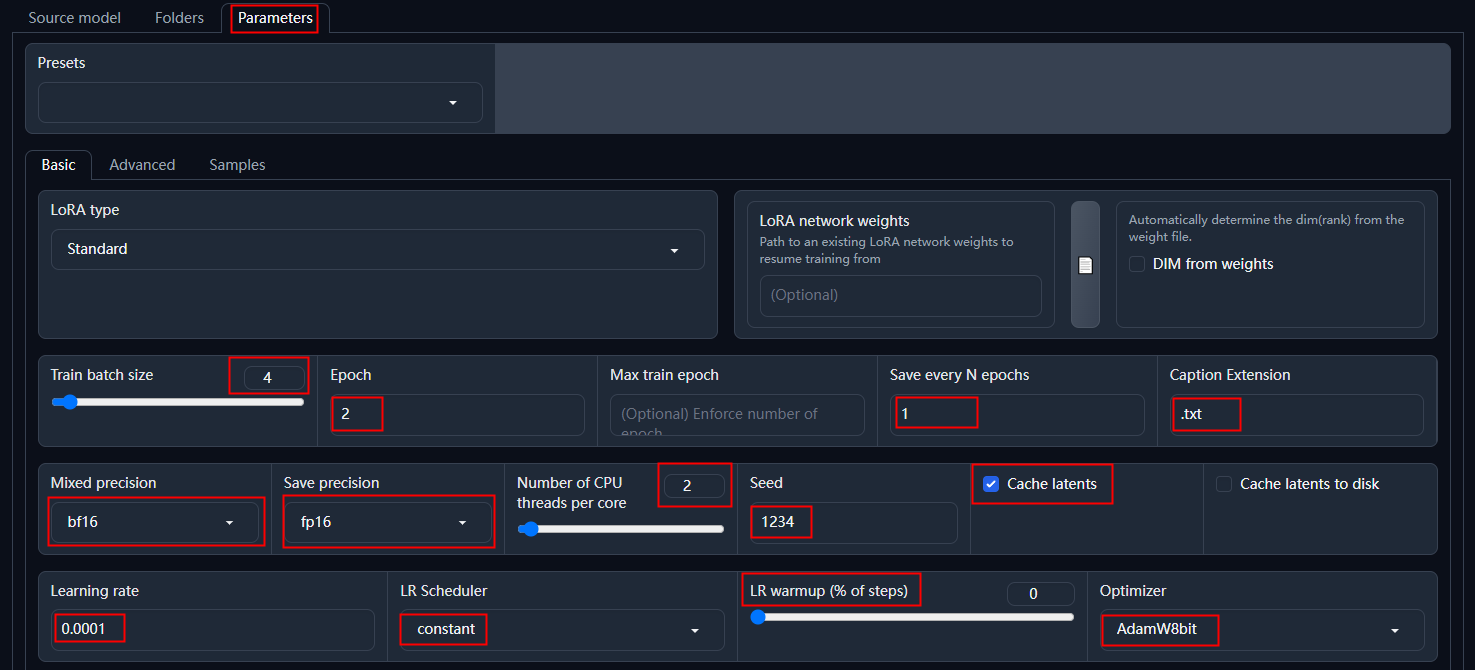
先来看基本参数(Basic):
- Train batch size:同时训练的样本图片数,默认为1,显存 12G 以上可以设置为2-6,请根据实际显存使用情况设置,数值越大训练速度越快。
- Epoch:训练的轮数,一轮就是把所有的样本图片完成一次训练。一般需要训练多轮,然后根据实际生图情况选择合适的轮次模型。轮数越大,训练需要的时间越多。
- Save every N epochs:每隔几轮保存一次训练出的模型,我们想要测试每一轮输出的模型,所以这里填写1。
- Caption Extension:样本图片对应的打标文件的后缀名,之前打标用的是 .txt,这里填上就行了。
- Mixed precision 和 Save precision:计算使用的浮点数精度控制,都选择fp16就好了,可以节省内存使用。bf16精度略低,但是表示的整数范围更大,数据类型转换也更容易,不过要看显卡能不能支持。
- Number of CPU threads per core:单个CPU核心的线程数,可以理解为一个CPU核心可以同时干两件事。一般都是2,我租用的这台服务器也是2,可以用 lscpu 等命令查看。不确定的设置为1。
- Seed:训练使用的随机数,随便填一个就行。如果需要提升之前构建过的模型(在 LoRA network weights 中填写之前构建过的模型),使用相同的随机数。
- Cache latents:勾选上,可以让训练速度更快。
- Learning rate:学习率,可以理解为每次学习走过的长度,值越小,训练的越慢,值越大,步子越大,就不容易找到规律,模型难以收敛。所谓收敛就是通过训练让模型不断得到优化的过程,难以收敛就是无法优化模型,模型生成的图片和样本图片偏差过大。
这一行都是有关学习率的参数设置,也就是怎么让模型收敛的又快又好,都是一些算法,先用我这里默认的吧,不好使再换。
- LR Scheduler:学习率调度器,它会自动调整学习率,我一般使用constant。
- LR warmup (% of steps):升温步数,仅在“LR Scheduler”为“constant_with_warmup”时设置,用来控制模型在训练前逐渐增加学习率的步数。
- Optimizer: 主要用来更新模型中的权重和偏差等参数,以便更好的拟合数据。有的优化器也可以直接影响学习率。先试试 AdamW8bit 吧。
- Max resolution:训练的最大分辨率,设置为样本图片的分辨率即可。
- Enable buckets:启动后支持多种分辨率的样本图片,程序会自动裁切,这里我已经都裁切成768了,勾不勾选无所谓了。
- Text Encoder learning rate:文本编码器的学习率,建议从0.00005开始,后面的Unet learning rate要比前面的大,设置成 0.0001,设置这个值会导致忽略上面的 Learing rate,保持一致吧。
- Network Rank:模型的神经网络参数维度,默认是8,建议 32、64、128,值越大模型越精细,生成的模型文件也越大。 Network Alpha 保持相同的值就好。




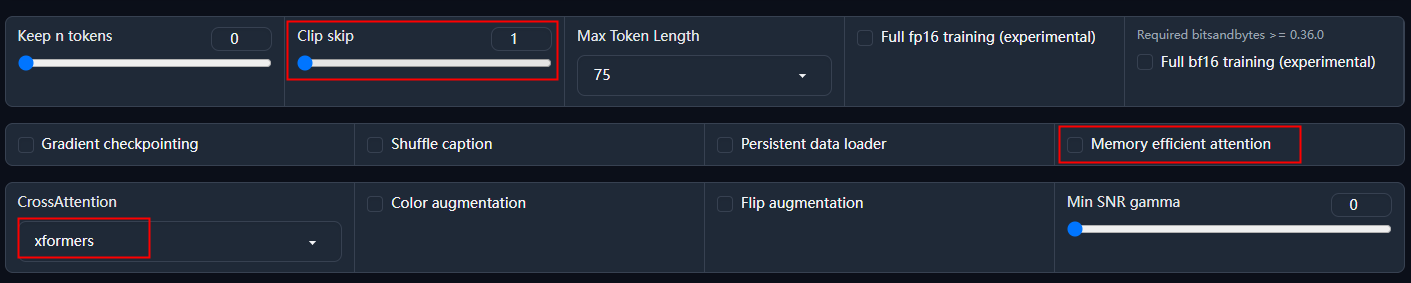
高级参数(Advanced)中我们看下这几个:
- Clip skip:默认为1。设置为大于1的数时,在训练时可以跳过一些处理,进而可以避免过拟合,增强模型的泛化能力,但也不易过大,会丢失特征。最好与对应大模型在训练时设置的参数相同。
- Memory efficient attention:可以优化显卡内存的使用,但会导致学习速度变慢。
- CrossAttention:用于关联图像和提示词的加速算法,一般就选择 xformers,加速图片生成并降低显存占用,xformers只适用于N卡,未来可能应用于其它显卡。
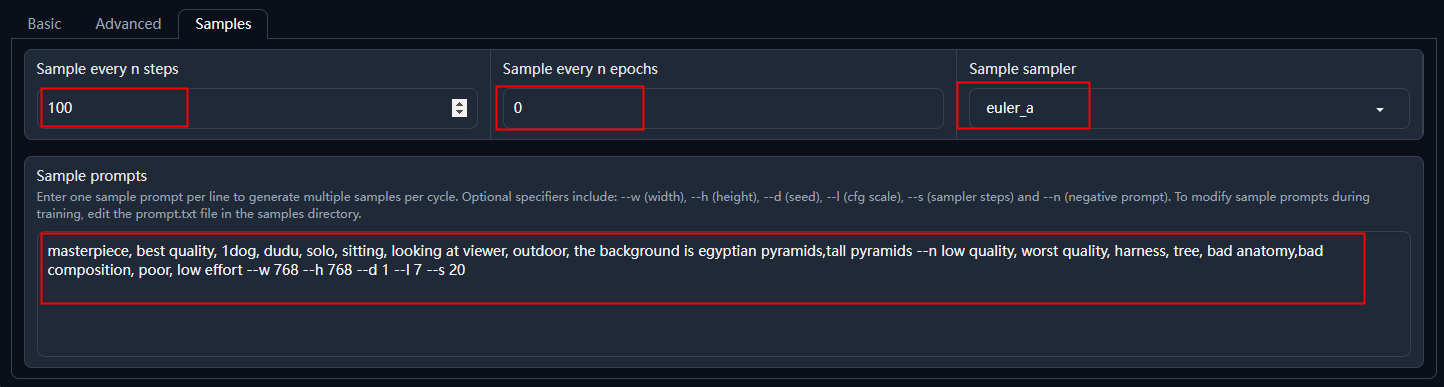
最后还有个采样参数(Samples),使用它可以跟踪训练效果:
Sample every n steps:每学习N步,生成一张图片。
Sample every n epochs:每学习N轮,生成一张图片,实测开启这个会覆盖 Sample every n steps。
Sample sampler:采样器,和SD WebUI中默认的采样器相同。
Sample prompts:采样提示词,这里包括了提示词、反向提示词、图片尺寸、采样步数等。
完成训练
点击“Start Training”之后,还是到控制台中查看处理进度。
因为每张图片学习100步,同时训练的数量是1,所以25张图片训练一次就要学习2500步,同时指定了轮次是3,所以总计是7500步。

训练完成后,可以看到 100% 的提示,模型已经保存到相应的目录。

测试
模型训练好了,怎么知道好不好使呢?那当然要做测试时,实际抽抽卡。
笨点的办法就是挨个测试,测试不同权重、提示词、大模型等情况下的表现。
这里分享一个快速对比测试的方法,使用 X/Y/Z图表。
在提示词中增加变量,如下图所示的样子引用Lora模型:
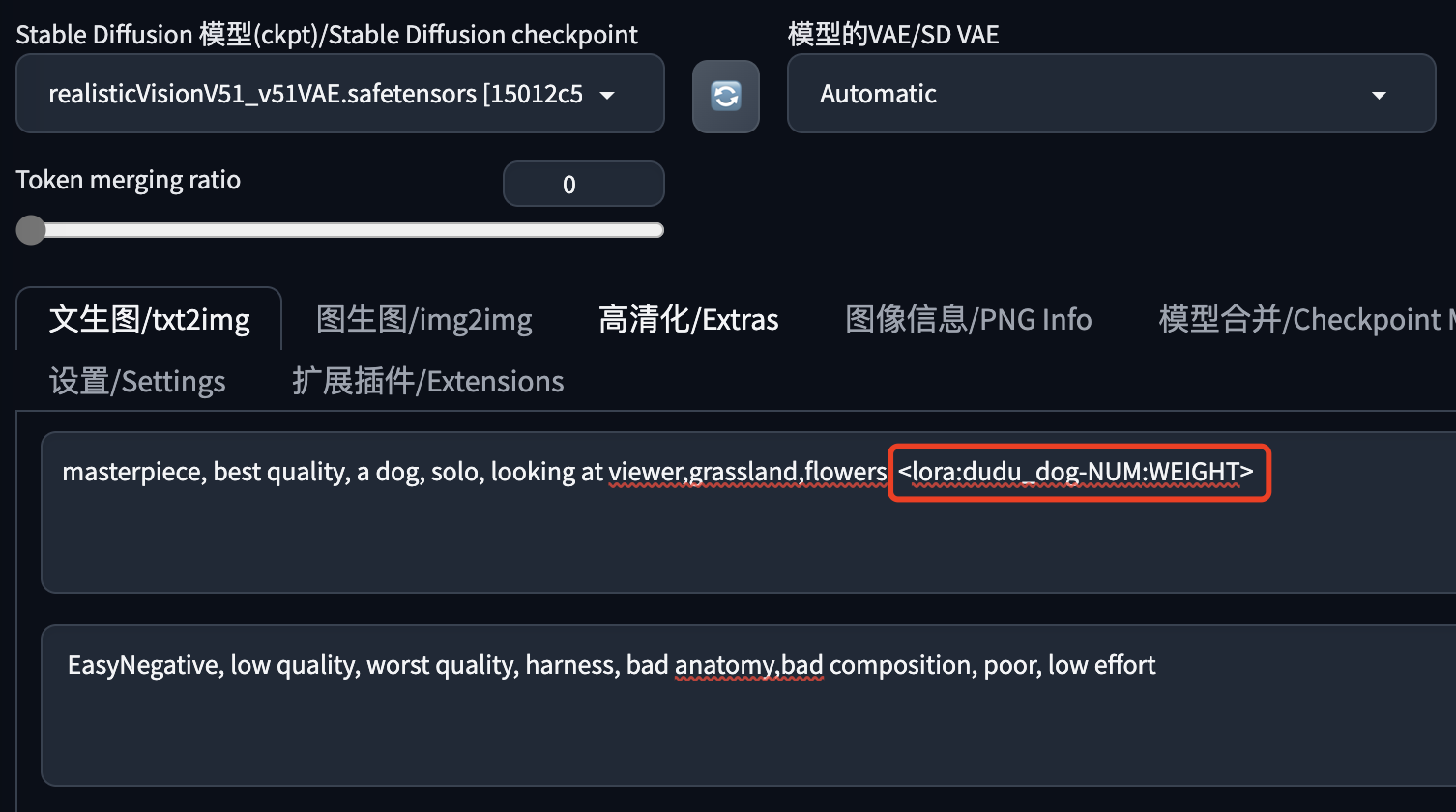
注意这里的:<lora:dudu_log-NUM:WEIGHT> ,NUM和WEIGHT是两个变量。
- NUM:因为我使用了多轮次的训练,获得了多个Lora模型,所以需要测试不同训练轮次的模型表现,这些模型的名字是有规律的:dudu_log-000001、dudu_log-000002、... ,每增加一轮训练,生成的模型名字序号就会加1。NUM 就是代表 000001、000002 的变量。
- WEIGHT 是使用当前 Lora 模型的权重变量,这里要测试不同权重下模型的表现。
X/Y/Z图表在文生图、图生图页面的最下方:
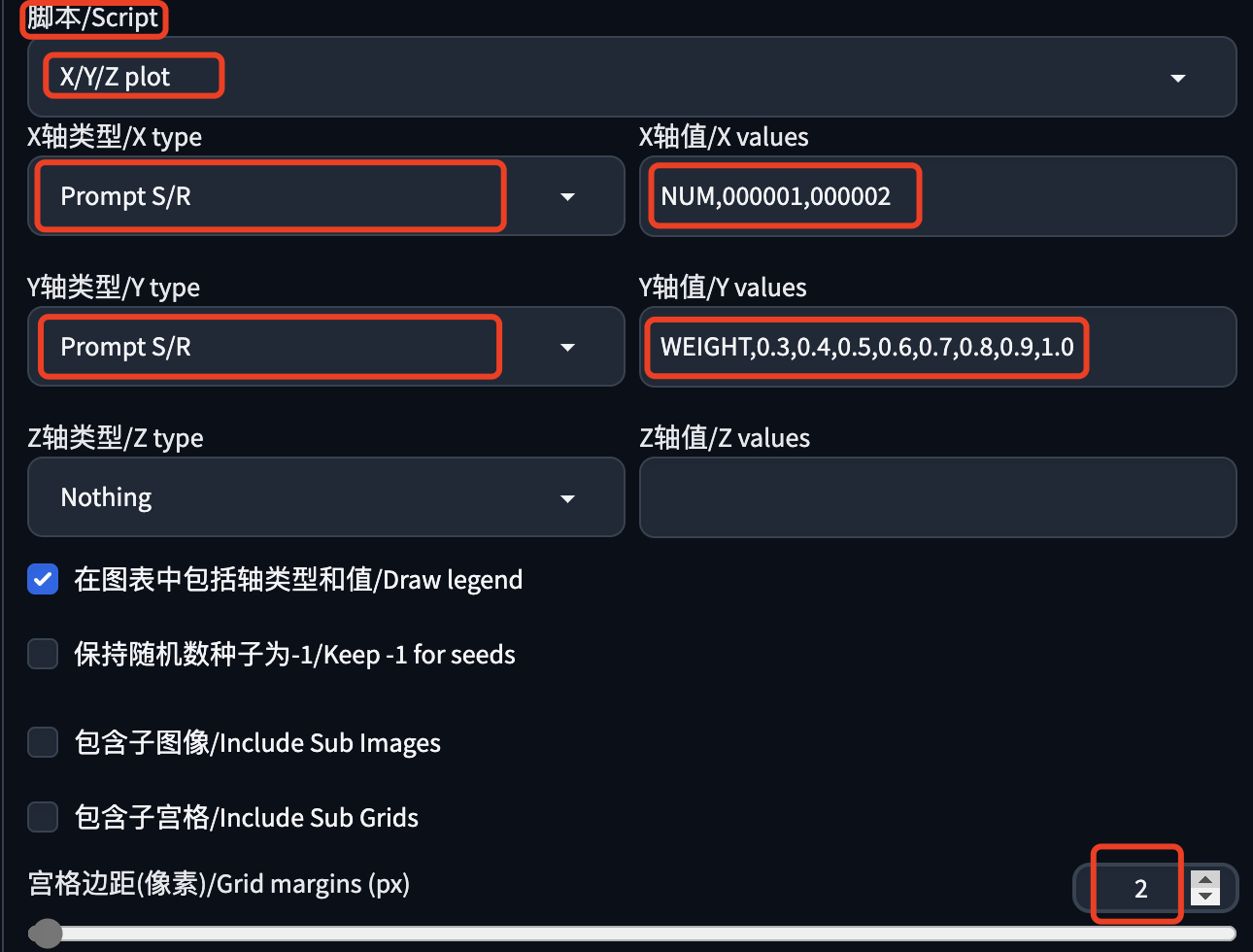
脚本类型选择:X/Y/Z图表:
X轴类型选择:Prompt S/R,X轴值填写:NUM,000001,000002
Y轴类型选择:Prompt S/R,Y轴值填写:WEIGHT,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1
空格边距填写:2,生成的图片之间做个分割。
然后我们去生成图片,生成图表如下:

然后我们就可以对比不同模型、权重下的出图效果,我这里模型 000002 更接近真实图片,权重 0.5-0.9 效果会比较好,1.0就有点过拟合了。
X/Y/Z图表中还有很多的维度可以测试,比如大模型、迭代步数、采样器、提示词引导系统等等,有兴趣的可以多去尝试下。
优化
仅分享我的一点经验和体会。上面也提到了一些,这里做个总结。
- 训练用的图片一定要高清,不要模糊,角色尽量多角度,原图对训练结果的差异特别大。如果没有高清的图,可以去 SD WebUI 的图生图中重绘模糊的图片,或者使用其它的软件高清化图片。
- 训练用的提示词:在提示词中去掉你想在生成图片时保留的角色特征,增加你允许生成图片时替换的角色特征。比如你想保留角色的长头发,那就在提示词中去掉长头发,这样生成图片时就有很大的概率都是长头发;如果你想要角色的眼睛颜色可以替换,就在训练提示词中写上黑色眼睛,这样生成图片时就可以使用蓝色眼睛的提示来更换角色的眼睛颜色。
- 多轮次训练:训练一轮的效果可能不好,成本允许的话,建议多训练几轮,然后对比不同轮次下的模型出图效果,选择最适合的那个。
- 训练步数:每张图片训练多少次才合适?训练的少了提取的特征不够,训练多了容易过拟合。二次元建议15-30次,其它图片50-100次。训练的图片少,每张图就可以多训练几次,训练的图片多,每张图就可以少训练几次。
资源下载
本文使用的模型、插件,生成的图片,都已经上传到了我整理的SD绘画资源中,后续也会持续更新,如有需要,请关注公众号:萤火遛AI(yinghuo6ai),发消息:SD,即可获取下载地址。
以上就是本文的主要内容,如有问题欢迎留言讨论。
[AI] Stable Diffusion基础:精准控制之ControlNet
[AI] Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
[AI] Stable Diffusion基础:ControlNet之图像提示(垫图)
[AI] Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
Stable Diffusion基础:精准控制之ControlNet
Stable Diffusion基础:ControlNet之重新上色(黑白照片换新颜)
Stable Diffusion基础:ControlNet之图像提示(垫图)
Stable Diffusion WebUI插件:StyleSelectorXL 之七十七种绘画风格任君选择
手把手教你在云环境炼丹:Stable Diffusion LoRA 模型保姆级炼制教程
Stable Diffusion基础:ControlNet之图片高仿
Stable Diffusion基础:ControlNet之人体姿势控制
SDXL 1.0出图效果直逼Midjourney!手把手教你快速体验!
AI抠图使用指南:Stable Diffusion WebUI Rembg实用技巧